Jak zdefiniować maksymalny rozmiar kolejki, pracowników i użyć multiprocessingu w generatorze keras fit ()?
Stosuję transfer-learning w wstępnie przeszkolonej sieci przy użyciu wersji GPU keras. Nie rozumiem jak zdefiniować parametry max_queue_size, workers, oraz use_multiprocessing. Jeśli zmienię te parametry (przede wszystkim w celu przyspieszenia nauki), nie jestem pewien, czy wszystkie dane są nadal widoczne na epoce.
max_queue_size:
Maksymalny rozmiar wewnętrznej kolejki treningowej, która służy do" precache " próbek z generatora
pytanie: czy odnosi się to do tego, ile partii jest przygotowanych na CPU? Jak to jest związane z
workers? Jak ją optymalnie zdefiniować?
workers:
Liczba wątków generujących partie równolegle. Procesory te są przetwarzane równolegle na procesorze i przekazywane na procesor GPU do obliczeń sieci neuronowych [18]}
pytanie: Jak mogę dowiedzieć się, ile partii mój procesor może / powinien generować równolegle?
use_multiprocessing:
-
Czy używać wątków opartych na procesie
pytanie: Czy muszę ustawić ten parametr na true, jeśli zmienię
workers? Czy dotyczy to użycia procesora?
Podobne pytania można znaleźć tutaj:
- szczegółowe wyjaśnienie modelu.parametry fit_generator (): wielkość kolejki, workery i use_multiprocessing
Do czego służy parametr "max_q_size"w modelu".fit_generator"?
Używam fit_generator() w następujący sposób:
history = model.fit_generator(generator=trainGenerator,
steps_per_epoch=trainGenerator.samples//nBatches, # total number of steps (batches of samples)
epochs=nEpochs, # number of epochs to train the model
verbose=2, # verbosity mode. 0 = silent, 1 = progress bar, 2 = one line per epoch
callbacks=callback, # keras.callbacks.Callback instances to apply during training
validation_data=valGenerator, # generator or tuple on which to evaluate the loss and any model metrics at the end of each epoch
validation_steps=
valGenerator.samples//nBatches, # number of steps (batches of samples) to yield from validation_data generator before stopping at the end of every epoch
class_weight=classWeights, # optional dictionary mapping class indices (integers) to a weight (float) value, used for weighting the loss function
max_queue_size=10, # maximum size for the generator queue
workers=1, # maximum number of processes to spin up when using process-based threading
use_multiprocessing=False, # whether to use process-based threading
shuffle=True, # whether to shuffle the order of the batches at the beginning of each epoch
initial_epoch=0)
Specyfikacja mojej Maszyny to:
CPU : 2xXeon E5-2260 2.6 GHz
Cores: 10
Graphic card: Titan X, Maxwell, GM200
RAM: 128 GB
HDD: 4TB
SSD: 512 GB
1 answers
Q_0:
Pytanie: czy to odnosi się do tego, ile partii jest przygotowanych na CPU? Jak jest to związane z pracownikami? Jak ją optymalnie zdefiniować?
Z opublikowanego linku można dowiedzieć się, że procesor nadal tworzy partie, dopóki kolejka nie osiągnie maksymalnego rozmiaru kolejki lub nie osiągnie przystanku. Chcesz mieć gotowe partie, aby twój GPU "wziął", aby GPU nie musiał czekać na procesor. Idealną wartością dla rozmiaru kolejki byłoby jej duże wystarczy, że twój GPU zawsze działa blisko maksimum i nigdy nie musi czekać, aż procesor przygotuje nowe partie.
Q_1:
Pytanie: Jak mogę dowiedzieć się, ile partii mój procesor może/powinien generować równolegle?
Jeśli widzisz, że procesor graficzny pracuje na biegu jałowym i czeka na partie, spróbuj zwiększyć liczbę pracowników, a być może także rozmiar kolejki.
Q_2:
Czy muszę ustawić ten parametr na true, jeśli zmienię workery? Czy dotyczy to Użycie procesora?
Tutaj {[12] } jest praktyczna analiza tego, co się dzieje, gdy ustawisz go na True LUB False. tutaj jest zalecenie, aby ustawić go na False, aby zapobiec zamarzaniu (w mojej konfiguracji True działa dobrze bez zamrażania). Być może ktoś inny może zwiększyć nasze zrozumienie tematu.
W podsumowaniu:
Spróbuj nie mieć sekwencyjnej konfiguracji, spróbuj włączyć procesor, aby zapewnić wystarczającą ilość danych dla GPU.
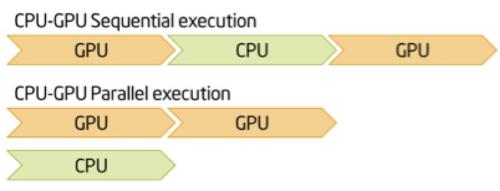
Również: można (powinno?) create kilka pytań następnym razem, aby łatwiej było na nie odpowiedzieć.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2019-04-16 13:46:06