Czym jest "Entropia i zysk z informacji"?
Czytam tę książkę (NLTK) i jest to mylące. Entropia jest zdefiniowana jako :
Entropia jest sumą prawdopodobieństwa każdej etykiety razy prawdopodobieństwo logowania tej samej etykiety
Jak zastosować entropię i maksymalną entropię w odniesieniu do eksploracji tekstu? Może mi ktoś podać prosty przykład (wizualny)?
7 answers
Zakładam, że entropia została wspomniana w kontekście budowania drzewa decyzyjne.
Aby zilustrować, wyobraź sobie zadanieuczenia się klasyfikowaniaimion na grupy męskie/żeńskie. Aby otrzymać listę imion, z których każda oznaczona jest m lub f, chcemy nauczyć się Modelu , który pasuje do danych i może być użyty do przewidywania płci nowego niewidzialnego imienia.
name gender
----------------- Now we want to predict
Ashley f the gender of "Amro" (my name)
Brian m
Caroline f
David m
Pierwszym krokiem jest podjęcie decyzji co funkcje dane są istotne dla klasy docelowej, którą chcemy przewidzieć. Niektóre przykładowe funkcje obejmują: pierwsza / ostatnia litera, długość, liczba samogłosek, czy kończy się samogłoską, itp.. Tak więc po wyodrębnieniu funkcji nasze dane wyglądają następująco:
# name ends-vowel num-vowels length gender
# ------------------------------------------------
Ashley 1 3 6 f
Brian 0 2 5 m
Caroline 1 4 8 f
David 0 2 5 m
length<7
| num-vowels<3: male
| num-vowels>=3
| | ends-vowel=1: female
| | ends-vowel=0: male
length>=7
| length=5: male
W zasadzie każdy węzeł reprezentuje test wykonywany na jednym atrybucie i idziemy w lewo lub w prawo w zależności od Wynik badania. Poruszamy się po drzewie, aż dotrzemy do węzła liścia, który zawiera predykcję klasy (m lub f)
Więc jeśli uruchomimy nazwę Amro w tym drzewie, zaczniemy od sprawdzenia " czy długość jest" a odpowiedź brzmi tak , więc idziemy w dół tej gałęzi. Po gałąź, następny test " jest liczba samogłosek " ponownie ocenia na true . Prowadzi to do węzła liścia oznaczonego m, a zatem przewidywanie jest mężczyzna (tak się składa, że jestem, więc drzewo przewidział wynik poprawnie ).
Drzewo decyzyjne jest zbudowane w sposób odgórny , ale pytanie brzmi jak wybrać, który atrybut podzielić na każdym węźle? Odpowiedź brzmi: znajdź cechę, która najlepiej dzieli klasę docelową na najczystsze możliwe węzły dziecięce (tj. węzły, które nie zawierają mieszanki zarówno męskiej, jak i żeńskiej, a raczej czyste węzły z tylko jedną klasą).
Ta miara czystość nazywa się Informacje. Reprezentuje oczekiwaną ilość informacji, która byłaby potrzebna do określenia, czy nowa instancja (imię) powinna być sklasyfikowana jako męska czy żeńska, biorąc pod uwagę przykład, który dotarł do węzła. Obliczamy to na podstawie liczby klas męskich i żeńskich w węźle.
Entropia Z drugiej strony jest miarą nieczystości (odwrotnie). Jest ona zdefiniowana dla Klasa binarna z wartościami a/b as:
Entropy = - p(a)*log(p(a)) - p(b)*log(p(b))
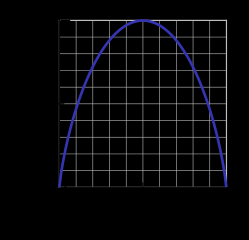
Ta funkcja entropii binarnej jest przedstawiona na poniższym rysunku (zmienna losowa może przyjmować jedną z dwóch wartości). Osiąga swoje maksimum, gdy prawdopodobieństwo wynosi p=1/2, co oznacza, że p(X=a)=0.5 lub podobnie p(X=b)=0.5 ma 50%/50% szans na bycie a lub b (niepewność jest maksymalna). Funkcja entropii jest zerowa, gdy prawdopodobieństwo wynosi p=1 lub {[23] } z całkowitą pewnością (p(X=a)=1 lub p(X=a)=0 odpowiednio, Ostatnie implikuje p(X=b)=1).
Oczywiście definicja entropii może być uogólniona dla dyskretnej zmiennej losowej X Z N wynikami (nie tylko dwoma):
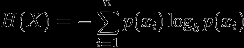
(log we wzorze przyjmuje się zwykle jako logarytm do Bazy 2)
Wracając do naszego zadania klasyfikacji nazw, spójrzmy na przykład. Wyobraź sobie, że w pewnym momencie podczas procesu budowy drzewa, byliśmy biorąc pod uwagę następujący podział:
ends-vowel
[9m,5f] <--- the [..,..] notation represents the class
/ \ distribution of instances that reached a node
=1 =0
------- -------
[3m,4f] [6m,1f]
Jak widzicie, przed rozłamem mieliśmy 9 samców i 5 samic, tj. P(m)=9/14 i P(f)=5/14. Zgodnie z definicją entropii:
Entropy_before = - (5/14)*log2(5/14) - (9/14)*log2(9/14) = 0.9403
Następnie porównujemy ją z entropią obliczoną po rozważeniu podziału, patrząc na dwie gałęzie potomne. W lewej gałęzi ends-vowel=1 mamy:
Entropy_left = - (3/7)*log2(3/7) - (4/7)*log2(4/7) = 0.9852
I prawą gałąź ends-vowel=0 mamy:
Entropy_right = - (6/7)*log2(6/7) - (1/7)*log2(1/7) = 0.5917
Łączymy lewe / prawe entropie używając liczby instancji w dół każda gałąź jako współczynnik wagowy (7 instancji poszło w lewo, a 7 w prawo), a po podziale otrzymujemy ostateczną entropię:
Entropy_after = 7/14*Entropy_left + 7/14*Entropy_right = 0.7885
Teraz porównując entropię przed i po podziale, otrzymujemy miarę pozyskiwanie informacji, czy też ile informacji uzyskaliśmy wykonując podział przy użyciu tej konkretnej funkcji: {]}
Information_Gain = Entropy_before - Entropy_after = 0.1518
powyższe obliczenia można zinterpretować w następujący sposób: wykonując podział za pomocą funkcji end-vowels, byliśmy w stanie zmniejszyć niepewność w wyniku predykcji sub-drzewa o niewielką ilość 0,1518 (mierzone w bitach jako Jednostki informacji ).
W każdym węźle drzewa, obliczenia te są wykonywane dla każdej funkcji, a cecha z największym przyrostem informacji jest wybierana do podziału w sposóbchciwy (w ten sposób faworyzuje cechy, które wytwarzajączysty podział z niską niepewnością/entropią). Proces ten jest stosowany recursively from the root-node down, and stops when a leaf node contains instances all having the same class (no need to split it further).
Zauważ, że pominąłem niektóre szczegóły , które wykraczają poza zakres tego postu, w tym jak obsługiwać funkcje numeryczne, brakujące wartości, przesiąkanie i przycinanie drzew itp..
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2016-02-04 13:01:23
Na początek, najlepiej byłoby zrozumieć the measure of information.
Jak mamy measure Informacje?
Kiedy dzieje się coś nieprawdopodobnego, mówimy, że to wielka wiadomość. Ponadto, kiedy mówimy coś przewidywalnego, to nie jest to naprawdę interesujące. Aby więc obliczyć to interesting-ness, funkcja powinna spełniać
- Jeśli prawdopodobieństwo zdarzenia wynosi 1( przewidywalne), to funkcja daje 0
- Jeśli prawdopodobieństwo zdarzenia jest bliskie 0, to funkcja powinna dawać wysokie liczba
- Jeśli prawdopodobieństwo 0,5 zdarzenia się wydarzy, podaje
one bitinformacje.
Jedną z miar naturalnych spełniających ograniczenia jest
I(X) = -log_2(p)
Gdzie p jest prawdopodobieństwem zdarzenia X. A jednostka jest w bit, tego samego bitu używa komputer. 0 LUB 1.
Przykład 1
Sprawiedliwy rzut monetą:
Ile informacji możemy uzyskać z jednego rzutu monetą?
Odpowiedź: -log(p) = -log(1/2) = 1 (bit)
Przykład 2
Jeśli meteor uderzy Ziemia jutro, p=2^{-22} wtedy będziemy mogli uzyskać 22 bity informacji.
Jeśli słońce wschodzi jutro, p ~ 1 wtedy jest 0 bit informacji.
Entropia
Więc jeśli weźmiemy pod uwagę interesting-ness zdarzenia Y, to jest to Entropia.
tj. Entropia jest wartością oczekiwaną interesującego zdarzenia.
H(Y) = E[ I(Y)]
Bardziej formalnie Entropia jest oczekiwaną liczbą bitów zdarzenia.
Przykład
Y = 1: Zdarzenie X występuje z prawdopodobieństwo p
Y = 0: Zdarzenie X nie zachodzi z prawdopodobieństwem 1-P
H(Y) = E[I(Y)] = p I(Y==1) + (1-p) I(Y==0)
= - p log p - (1-p) log (1-p)
Baza logów 2 dla wszystkich logów.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2014-10-17 04:37:04
Nie mogę dać ci grafiki, ale może dam ci jasne wyjaśnienie.
Załóżmy, że mamy kanał informacyjny, taki jak światło, które miga raz dziennie na czerwono lub na Zielono. Ile informacji przekazuje? Pierwsze odgadnięcie może być jednym bitem dziennie. Ale co jeśli dodamy niebieski, aby nadawca miał trzy opcje? Chcielibyśmy mieć miarę informacji, która może obsługiwać rzeczy inne niż potęgi dwóch, ale nadal być addytywna (sposób, w jaki mnożenie liczby możliwe wiadomości przez dwa dodaje jeden bit). Możemy to zrobić, biorąc log2(liczba możliwych wiadomości), ale okazuje się, że jest bardziej ogólny sposób.
Załóżmy, że wracamy do czerwonego / zielonego, ale czerwona żarówka się wypaliła (to powszechna wiedza), więc lampa musi zawsze migać na Zielono. Kanał jest teraz bezużyteczny, wiemy, jaki będzie następny błysk {[7] } więc błyski nie przekazują żadnych informacji, żadnych wiadomości. Teraz naprawiamy żarówkę, ale narzucamy zasadę, że czerwona żarówka może nie błysk dwa razy z rzędu. Kiedy lampa miga na Czerwono, wiemy, jaki będzie następny błysk. Jeśli spróbujesz wysłać strumień bitowy przez ten kanał, przekonasz się, że musisz zakodować go z większą liczbą błysków niż masz bity (w rzeczywistości o 50% więcej). A jeśli chcesz opisać sekwencję błysków, możesz to zrobić z mniejszą ilością bitów. To samo dotyczy przypadku, gdy każdy błysk jest niezależny (bez kontekstu), ale zielone błyski są bardziej powszechne niż czerwone: im bardziej Przekrzywione prawdopodobieństwo, tym mniej bitów trzeba opisać Sekwencja, a im mniej zawiera informacji, aż do całej zielonej, wypalonej żarówki.
Okazuje się, że istnieje sposób na zmierzenie ilości informacji w sygnale, na podstawie prawdopodobieństwa różnych symboli. Jeśli prawdopodobieństwo otrzymania symbolu xi wynosi p i , to rozważmy Ilość
-log pi
Im mniejsze p i , tym większa jest ta wartość. Jeśli x i stanie się dwa razy mniej prawdopodobne, wartość ta wzrośnie o stałą kwotę (log (2)). Powinno to przypominać o dodaniu jednego bitu do wiadomości.
Jeśli nie wiemy, jaki będzie symbol (ale znamy prawdopodobieństwo), możemy obliczyć średnią tej wartości, ile otrzymamy, sumując różne możliwości:
I = -Σ pi log(pi)
To jest zawartość informacyjna w jednym flashu.
Red bulb burnt out: pred = 0, pgreen=1, I = -(0 + 0) = 0 Red and green equiprobable: pred = 1/2, pgreen = 1/2, I = -(2 * 1/2 * log(1/2)) = log(2) Three colors, equiprobable: pi=1/3, I = -(3 * 1/3 * log(1/3)) = log(3) Green and red, green twice as likely: pred=1/3, pgreen=2/3, I = -(1/3 log(1/3) + 2/3 log(2/3)) = log(3) - 2/3 log(2)
Jest to treść informacji, czyli Entropia wiadomości. Jest maksymalna, gdy różne symbole są wyposażone. Jeśli jesteś fizykiem używasz log naturalny, jeśli jesteś informatykiem używasz log2 i zdobądź kawałki.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2009-12-07 13:45:44
Naprawdę polecam przeczytać o teorii informacji, metodach bayesowskich i MaxEnt. Na początek jest to (bezpłatnie dostępna online) książka Davida Mackaya:
Http://www.inference.phy.cam.ac.uk/mackay/itila/
Te metody wnioskowania są o wiele bardziej ogólne niż tylko Text mining i nie mogę naprawdę wymyślić, jak można nauczyć się, jak zastosować to do NLP bez uczenia się niektórych ogólnych podstaw zawartych w tej książce lub innych książkach wprowadzających na maszynie Nauka i MaxEnt metody bayesowskie.
Związek między entropią a teorią prawdopodobieństwa z przetwarzaniem i przechowywaniem informacji jest naprawdę, naprawdę głęboki. Aby dać temu posmak, istnieje twierdzenie Shannona, które mówi, że maksymalna ilość informacji, którą można przekazać bez błędu przez hałaśliwy kanał komunikacyjny, jest równa entropii procesu szumu. Istnieje również twierdzenie, które łączy, ile można skompresować kawałek danych, aby zająć minimum możliwe pamięci w komputerze do entropii procesu, który wygenerował dane.
Myślę, że nie jest to naprawdę konieczne, abyś uczył się tych wszystkich twierdzeń z teorii komunikacji, ale nie jest możliwe, aby nauczyć się tego bez poznania podstaw o tym, czym jest Entropia, jak jest obliczana, jaki jest jej związek z informacją i wnioskowaniem itp...
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2009-12-14 17:42:55
Kiedy implementowałem algorytm do obliczania entropii obrazu, znalazłem te linki, patrz Tutaj i tutaj .
To jest pseudo-kod, którego użyłem, będziesz musiał dostosować go do pracy z tekstem, a nie obrazkami, ale zasady powinny być takie same.
//Loop over image array elements and count occurrences of each possible
//pixel to pixel difference value. Store these values in prob_array
for j = 0, ysize-1 do $
for i = 0, xsize-2 do begin
diff = array(i+1,j) - array(i,j)
if diff lt (array_size+1)/2 and diff gt -(array_size+1)/2 then begin
prob_array(diff+(array_size-1)/2) = prob_array(diff+(array_size-1)/2) + 1
endif
endfor
//Convert values in prob_array to probabilities and compute entropy
n = total(prob_array)
entrop = 0
for i = 0, array_size-1 do begin
prob_array(i) = prob_array(i)/n
//Base 2 log of x is Ln(x)/Ln(2). Take Ln of array element
//here and divide final sum by Ln(2)
if prob_array(i) ne 0 then begin
entrop = entrop - prob_array(i)*alog(prob_array(i))
endif
endfor
entrop = entrop/alog(2)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2009-12-07 13:35:46
Nieformalnie
Entropia to dostępność informacji lub wiedzy, brak informacji prowadzi do trudności w przewidywaniu przyszłości, która jest wysoka Entropia (next word prediction in text mining), a dostępność informacji / wiedzy pomoże nam bardziej realistyczne przewidywanie przyszłości (low entropy).
Istotne informacje dowolnego typu zmniejszą entropię i pomogą nam przewidzieć bardziej realistyczną przyszłość, że Informacje mogą być słowo "mięso" jest obecne w zdanie lub słowo "mięso" nie występuje. To się nazywa Information Gain
Formalnie
Entropia jest brakiem kolejności przewidywalności
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-08-01 17:26:59
Jak czytasz ksiazke o NLTK to byloby ciekawie przeczytac O Module Maxent Classifier http://www.nltk.org/api/nltk.classify.html#module-nltk.classify.maxent
Klasyfikacja górnictwa tekstowego może obejmować: wstępne przetwarzanie (tokenizacja, parowanie, wybór funkcji z uzyskaniem informacji ...), transformacja na numeryczną (frequency lub TF-IDF) (myślę, że jest to kluczowy krok do zrozumienia przy użyciu tekstu jako wejścia do algorytmu, który akceptuje tylko numeryczne), a następnie klasyfikować za pomocą MaxEnt, na pewno jest to tylko przykład.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-03-26 12:33:51