Jaka jest różnica między ASCII a Unicode?
Jaka jest dokładna różnica między Unicode a ASCII?
ASCII ma w sumie 128 znaków (256 w rozszerzonym zestawie).
Czy jest jakaś Specyfikacja rozmiaru dla znaków Unicode?
9 answers
ASCII definiuje 128 znaków, które odwzorowują liczby 0-127. Unicode definiuje (mniej niż) 221 znaków, które podobnie odwzorowują liczby 0-221 (chociaż nie wszystkie numery są obecnie przypisane, a niektóre są zarezerwowane).
Unicode jest supersetem ASCII, a liczby 0-127 mają w ASCII takie samo znaczenie jak w Unicode. Na przykład liczba 65 oznacza "łacińskie wielkie 'A'".
Ponieważ znaki Unicode zazwyczaj nie mieszczą się w jednym 8-bitowym bajcie, istnieje wiele sposobów przechowywania znaków Unicode w sekwencjach bajtów, takich jak UTF-32 i UTF-8.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2019-07-06 22:51:08
Zrozumienie Dlaczego ASCII i Unicode zostały stworzone w pierwszej kolejności pomogło mi zrozumieć różnice między nimi.
ASCII, Origins
Jak podano w innych odpowiedziach, ASCII używa 7 bitów do reprezentowania znaku. Używając 7 bitów, możemy mieć maksymalnie 2^7 (= 128) różnych kombinacji*. Co oznacza, że możemy reprezentować maksymalnie 128 znaków.
Czekaj, 7 bitów? Ale dlaczego nie 1 bajt (8 bitów)?
Ostatni bit (8th) jest używany do unikania błędów jako bit parzystości. To było istotne lata temu.
Większość znaków ASCII to drukowalne znaki alfabetu, takie jak abc, ABC, 123,?&!, itd. Pozostałe to znaki sterujące , takie jak powrót karetki, kanał linii , tabulator itp.
Zobacz poniżej binarną reprezentację kilku znaków w ASCII:
0100101 -> % (Percent Sign - 37)
1000001 -> A (Capital letter A - 65)
1000010 -> B (Capital letter B - 66)
1000011 -> C (Capital letter C - 67)
0001101 -> Carriage Return (13)
Zobacz pełną tabelę ASCII tutaj .
ASCII było przeznaczone dla angielskiego tylko.
Co? Dlaczego tylko angielski? Tak wiele języków tam!
Ponieważ centrum przemysłu komputerowego znajdowało się w USA w tym czas. W konsekwencji nie musieli wspierać akcentów ani innych znaki takie jak á, ü, ç, ñ itp. (aka znaki diakrytyczne ).
ASCII Extended
Niektórzy sprytni ludzie zaczęli używać 8-tego bitu (bit używany do parzystości) do kodowania większej liczby znaków obsługujących ich język (aby wspierać "é" , w języku francuskim, na przykład). Użycie jednego dodatkowego bitu podwoiło rozmiar oryginalnej tabeli ASCII, aby zmapować do 256 znaków (2^8 = 256 znaków). A nie 2^7 jak poprzednio (128).
10000010 -> é (e with acute accent - 130)
10100000 -> á (a with acute accent - 160)
Nazwa tego "ASCII rozszerzone do 8 bitów, a nie 7 bitów jak wcześniej" może być po prostu określana jako "rozszerzone ASCII "lub"8-bitowe ASCII".
Jako @Tom zauważył w swoim komentarzu poniżej, że nie ma czegoś takiego jak " rozszerzone ASCII ", ale jest to łatwy sposób na odniesienie się do tej sztuczki 8-bitowej. Są wiele odmian 8-bitowej tabeli ASCII, na przykład ISO 8859-1, zwany także ISO Latin-1 .
Unicode, The Rise
ASCII Extended rozwiązuje problem języków opartych na alfabecie łacińskim... a co z innymi potrzebującymi zupełnie innego alfabetu? Grek? Rosyjski? Chińczycy i tym podobne?
Potrzebowalibyśmy zupełnie nowego zestawu znaków... na tym polega racjonalność Unicode. Unicode nie zawiera każdego znaku z każdego język, ale na pewno zawiera gigantyczną ilość znaków (patrz ta tabela).
Nie można zapisać tekstu na dysku twardym jako "Unicode". Unicode jest abstrakcyjną reprezentacją tekstu. Musisz "zakodować" tę abstrakcyjną reprezentację. W tym miejscu wkracza kodowanie .
Kodowanie: UTF-8 vs UTF-16 vs UTF-32
Ta odpowiedź robi całkiem dobrą robotę w wyjaśnianiu podstaw:
- UTF-8 i UTF-16 to kodowania o zmiennej długości.
- w UTF-8 znak może zajmować minimum 8 bitów.
- w UTF-16 Długość znaku zaczyna się od 16 bitów. UTF-32 jest kodowaniem o stałej długości 32 bitów.
UTF-8 używa zestawu ASCII dla pierwszych 128 znaków. Jest to przydatne, ponieważ oznacza, że tekst ASCII jest również ważny w UTF-8.
Mnemotechnika:
- UTF-8: minimum 8 bity.
- UTF-16: minimum 16 bity.
- UTF-32: minimum i maksimum 32 bity.
Uwaga:
Dlaczego 2^7?
Dla niektórych jest to oczywiste, ale na wszelki wypadek. Mamy do dyspozycji siedem slotów wypełnionych 0 LUB 1 (kodem binarnym ). Każdy może mieć dwie kombinacje. Jeśli mamy siedem miejsc, mamy 2 * 2 * 2 * 2 * 2 * 2 * 2 = 2^7 = 128 kombinacje. Pomyśl o tym jak o zamku szyfrowym z siedmioma kołami, każde koło ma dwa numery tylko.
Źródło: Wikipedia, ten wspaniały wpis na blogu i Mocki.co gdzie początkowo zamieściłem to podsumowanie.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-07-31 21:53:41
ASCII ma 128 punktów kodowych, od 0 do 127. Może zmieścić się w pojedynczym 8-bitowym bajcie, wartości od 128 do 255 były używane dla innych znaków. Z niezgodnymi wyborami, powodując katastrofę strony kodowej . Tekst zakodowany na jednej stronie kodowej nie może być odczytany poprawnie przez program, który zakłada lub odgaduje na innej stronie kodowej.
Unicode przyszedł rozwiązać tę katastrofę. Wersja 1 zaczynała się od 65536 punktów kodowych, Zwykle zakodowanych w 16 bitach. Później rozszerzony w wersji 2 do 1,1 miliona punktów kodowych. Aktualna wersja to 6.3, wykorzystująca 110 187 z dostępnych 1,1 miliona punktów kodu. To już nie pasuje do 16 bitów.
Kodowanie w 16-bitach było powszechne, gdy pojawiła się Wersja 2, używana na przykład przez systemy operacyjne Microsoft i Apple. I środowiska uruchomieniowe takie jak Java. V2 Spec wymyślił sposób na mapowanie tych 1,1 miliona punktów kodu na 16-bitowe. Kodowanie zwane UTF-16, kodowanie o zmiennej długości, w którym jeden punkt kodu może zająć 2 lub 4 bajty. Na oryginalne punkty kodu v1 zajmują 2 bajty, dodane zajmują 4.
Innym kodowaniem o zmiennej długości, które jest bardzo popularne w systemach operacyjnych *nix i narzędziach, jest UTF-8, punkt kodu może trwać od 1 do 4 bajtów, oryginalne kody ASCII zajmują 1 bajt, reszta zajmuje więcej. Jedynym kodowaniem nie zmiennej długości jest UTF-32, zajmuje 4 bajty dla punktu kodowego. Nie jest często używany, ponieważ jest dość marnotrawny. Istnieją inne, jak UTF-1 i UTF-7, powszechnie ignorowane.
Problem z Kodowanie UTF-16/32 polega na tym, że kolejność bajtów zależy od endian-ness maszyny, która utworzyła strumień tekstowy. Więc dodaj do mieszanki UTF-16BE, UTF-16LE, UTF-32BE i UTF-32LE.
Posiadanie tych różnych opcji kodowania powoduje w pewnym stopniu katastrofę strony kodowej, wraz z gorącymi dyskusjami wśród programistów, który wybór UTF jest "najlepszy". Ich związek z domyślnymi systemami operacyjnymi prawie rysuje linie. Jednym z kontrśrodków jest definicja BOM, Znak porządku bajtów, specjalny punkt kodowy (U + FEFF, spacja o zerowej szerokości) na początku strumienia tekstowego, który wskazuje, w jaki sposób reszta strumienia jest zakodowana. Wskazuje zarówno kodowanie UTF, jak i endianess i jest neutralne dla silnika renderowania tekstu. Niestety jest to opcjonalne i wielu programistów twierdzi, że ma prawo go pominąć, więc wypadki są nadal dość powszechne.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-09-30 15:18:27
Java zapewnia wsparcie dla Unicode i. E obsługuje wszystkie alfabety świata. Stąd Rozmiar znaku w Javie wynosi 2 bajty. I zakres od 0 do 65535.

Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-01-07 06:28:19
ASCII ma 128 pozycji kodowych, przydzielonych znakom graficznym i znakom sterującym (kodom sterującym).
Unicode ma 1 114 112 pozycji kodu. Około 100 000 z nich zostało obecnie przydzielonych do znaków, a wiele punktów kodu zostało wykonanych na stałe (tzn. nigdy nie zostało użyte do kodowania żadnego znaku), a większość punktów kodu nie jest jeszcze przypisana.
Jedyne rzeczy, które ASCII i Unicode mają wspólne to: 1) są to kody znaków. 2) 128 pierwsze pozycje kodu Unicode mają takie same Znaczenie jak w ASCII, z tym wyjątkiem, że pozycje kodu znaków sterujących ASCII są po prostu zdefiniowane jako znaki sterujące, z nazwami odpowiadającymi ich nazwom ASCII, ale ich znaczenia nie są zdefiniowane w Unicode.
Czasami jednak Unicode jest scharakteryzowany (nawet w standardzie Unicode!) jako "wide ASCII". Jest to slogan, który przede wszystkim stara się przekazać ideę, że Unicode ma być uniwersalny kod znaków taki sam jak kiedyś był ASCII (choć repertuar znaków ASCII był beznadziejnie niewystarczający do uniwersalnego użycia), jako przeciwieństwo używania różnych kodów w różnych systemach i aplikacjach oraz w różnych językach.
Unicode jako taki definiuje tylko "rozmiar logiczny" znaków: każdy znak ma numer kodu w określonym zakresie. Te numery kodowe mogą być przedstawione za pomocą różnych kodowań transferowych, a wewnętrznie, w pamięci, Unicode znaki są zwykle reprezentowane przy użyciu jednej lub dwóch 16-bitowych ilości na znak, w zależności od zakresu znaków, czasami przy użyciu jednej 32-bitowej ilości na znak.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-04-04 18:53:15
ASCII i Unicode to dwa kodowania znaków. Zasadniczo są to standardy przedstawiania znaków różnicowych w postaci binarnej, aby mogły być zapisywane, przechowywane, przesyłane i odczytywane na nośnikach cyfrowych. Główną różnicą między nimi jest sposób kodowania znaku i liczba bitów, których używają dla każdego z nich. ASCII pierwotnie używało siedmiu bitów do kodowania każdego znaku. Ten został później zwiększony do ośmiu z rozszerzonym ASCII, aby rozwiązać pozorną nieadekwatność oryginał. W przeciwieństwie do tego, Unicode używa programu do kodowania zmiennych bitów, w którym można wybierać między kodowaniem 32, 16 i 8-bitowym. Użycie większej liczby bitów pozwala na użycie większej liczby znaków kosztem większych plików, podczas gdy mniejsza liczba bitów daje ograniczony wybór, ale oszczędzasz dużo miejsca. UTF-8 lub ASCII) byłoby prawdopodobnie najlepsze, jeśli kodujesz duży dokument w języku angielskim.
Jeden z głównych powodów, dla których Unicode był problemem, wynikał z wielu niestandardowych rozszerzonych ASCII programy. O ile nie korzystasz z rozpowszechnionej strony, używanej przez firmę Microsoft i większość innych firm programistycznych, prawdopodobnie napotkasz problemy z pojawianiem się znaków jako pól. Unicode praktycznie eliminuje ten problem, ponieważ wszystkie punkty kodu znaków zostały ustandaryzowane.
Kolejną ważną zaletą Unicode jest to, że maksymalnie może pomieścić ogromną liczbę znaków. Z tego powodu Unicode zawiera obecnie większość języków pisanych i nadal ma miejsce dla nawet więcej. Obejmuje to typowe Skrypty od lewej do prawej, takie jak angielski, a nawet Skrypty od prawej do lewej, takie jak arabski. Chiński, japoński i wiele innych wariantów są również reprezentowane w Unicode. Więc Unicode nie zostanie zastąpiony w najbliższym czasie.
W celu zachowania kompatybilności ze starszymi ASCII, które były już w powszechnym użyciu, Unicode został zaprojektowany w taki sposób, aby pierwsze osiem bitów pasowało do najpopularniejszej strony ASCII. Więc jeśli otworzysz plik zakodowany w ASCII dzięki Unicode nadal otrzymujesz prawidłowe znaki zakodowane w pliku. Ułatwiło to przyjęcie Unicode, ponieważ zmniejszyło wpływ przyjęcia nowego standardu kodowania dla tych, którzy już używali ASCII.
Podsumowanie:
1.ASCII uses an 8-bit encoding while Unicode uses a variable bit encoding.
2.Unicode is standardized while ASCII isn’t.
3.Unicode represents most written languages in the world while ASCII does not.
4.ASCII has its equivalent within Unicode.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-11-23 07:14:57
Przechowywanie
Podane liczby służą tylko do przechowywania 1 znaku
- ASCII ⟶ 27 bits (1 byte)
- Rozszerzone ASCII ⟶ 28 bits (1 bajt)
- UTF-8 minimum minimum 28, maksimum 232 bity (min 1, max 4 bajty)
- UTF-16 minimum minimum 216, maksimum 232 bity (min 2, max 4 bajty)
- UTF-32 ⟶ 232 bits (4 bajty)
Użycie (stan na Luty 2020)
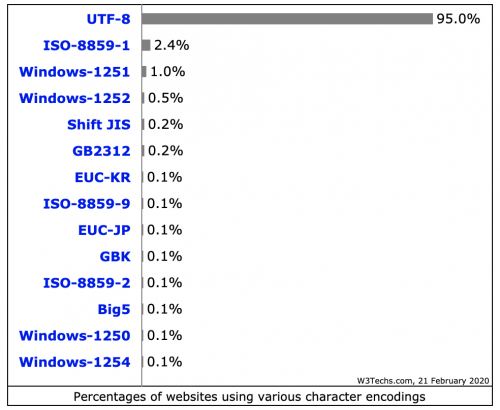
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-02-21 22:30:53
ASCII definiuje 128 znaków, ponieważ Unicode zawiera repertuar ponad 120 000 znaków.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-08-16 03:33:54
Poza tym, jak UTF jest supersetem ASCII, inną dobrą różnicą, jaką należy wiedzieć między ASCII a UTF, jest kodowanie plików na dysku, reprezentacja danych i przechowywanie w pamięci losowej. Programy wiedzą, że dane powinny być rozumiane jako ciąg znaków ASCII lub UTF poprzez wykrywanie specjalnych kodów znaków w kolejności bajtów na początku danych, lub przez założenie od intencji programisty, że dane są tekstem, a następnie sprawdzanie ich pod kątem wzorców, które wskazują, że są w jednym kodowaniu tekstu lub kolejny.
Używając konwencjonalnego zapisu przedrostkowego 0x dla danych szesnastkowych, podstawowym dobrym odniesieniem jest to, że tekst ASCII zaczyna się od wartości bajtów 0x00 do 0x7F reprezentujących jedną z możliwych wartości znaków ASCII . Tekst UTF jest zwykle oznaczany przez rozpoczynanie od bajtów 0xEF 0xBB 0xBF dla UTF8. Dla UTF16 używane są bajty startowe 0xFE 0xFF lub 0xFF 0xFE, z kolejnością endian-ness bajtów tekstowych wskazaną przez kolejność bajtów startowych. Prosta obecność wartości bajtów, które nie są w zakresie ASCII możliwych wartości bajtów wskazuje również, że dane są prawdopodobnie UTF.
Istnieją inne znaki kolejności bajtów , które używają różnych kodów do wskazania, że dane powinny być interpretowane jako tekst zakodowany w określonym standardzie kodowania.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2019-12-05 16:47:44