Jak mogę profilować kod C++ działający na Linuksie?
Mam aplikację C++, działającą na Linuksie, którą jestem w trakcie optymalizacji. Jak Mogę określić, które obszary mojego kodu działają powoli?
19 answers
Jeśli twoim celem jest użycie profilera, użyj jednego z sugerowanych.
Jednakże, jeśli się spieszysz i możesz ręcznie przerwać program pod debuggerem, gdy jest on subiektywnie powolny, istnieje prosty sposób na znalezienie problemów z wydajnością.
Wystarczy zatrzymać go kilka razy i za każdym razem spojrzeć na stos wywołań. Jeśli jest jakiś kod, który marnuje jakiś procent czasu, 20% lub 50% lub cokolwiek, to jest prawdopodobieństwo, że złapiesz go w ustawie o każda próbka. Tak więc, jest to mniej więcej procent próbek, na których go zobaczysz. Nie jest wymagane wykształcone zgadywanie. Jeśli masz zgadywanie, na czym polega problem, udowodni to lub obali.
Możesz mieć wiele problemów z wydajnością o różnych rozmiarach. Jeśli wyczyścisz którąkolwiek z nich, pozostałe będą miały większy procent i będą łatwiejsze do wykrycia w kolejnych przejazdach. Ten efekt powiększenia , gdy jest złożony z wielu problemów, może prowadzić do naprawdę ogromnych czynników przyspieszania.
Zastrzeżenie : Programiści są zwykle sceptyczni wobec tej techniki, chyba że sami jej nie użyli. Powiedzą, że profilerzy dają ci te informacje, ale jest to prawdą tylko wtedy, gdy próbkują cały stos połączeń, a następnie pozwalają zbadać losowy zestaw próbek. (Podsumowania są tam, gdzie wgląd jest stracony.) Wykresy połączeń nie dają tych samych informacji, ponieważ
- nie sumują się na poziomie instrukcji, oraz
- dają mylące podsumowania w obecności rekurencji.
Powiedzą również, że działa tylko na programach zabawkowych, kiedy w rzeczywistości działa na dowolnym programie, i wydaje się, że działa lepiej na większych programach, ponieważ mają więcej problemów do znalezienia. Powiedzą, że czasami znajduje rzeczy, które nie są problemami, ale jest to prawdą tylko wtedy, gdy widzisz coś {31]}raz {32]}. Jeśli widzisz problem na więcej niż jednej próbce, jest on prawdziwy.
P. S. to można to również zrobić w programach wielowątkowych, jeśli istnieje sposób na zbieranie próbek stosu wywołań puli wątków w pewnym momencie, tak jak ma to miejsce w Javie.
P. P. S ogólnie rzecz biorąc, im więcej warstw abstrakcji masz w swoim oprogramowaniu, tym bardziej prawdopodobne jest, że odkryjesz, że jest to przyczyna problemów z wydajnością(i możliwość uzyskania przyspieszenia).
Dodano: może nie jest to oczywiste, ale technika próbkowania stosu działa równie dobrze w obecność rekurencji. Powodem jest to, że czas, który zostanie zapisany przez usunięcie instrukcji jest przybliżony przez ułamek próbek zawierających go, niezależnie od liczby razy może wystąpić w próbce.
Innym zarzutem, który często słyszę, jest: "zatrzyma się w jakimś przypadkowym miejscu i ominie prawdziwy problem ". Wynika to z uprzedniego pojęcia, jaki jest prawdziwy problem. Kluczową właściwością problemów z wydajnością jest to, że przeczą one oczekiwaniom. Kontrola wyrywkowa mówi ci, że coś jest problemem, a twoja pierwsza reakcja to niedowierzanie. To naturalne, ale możesz być pewien, że jeśli znajdzie problem, jest prawdziwy i vice-versa.
Dodał: pozwól, że przedstawię bayesowskie wyjaśnienie, jak to działa. Załóżmy, że istnieje instrukcja I (wywołanie lub w inny sposób), która znajduje się na stosie wywołania jakiegoś ułamka f czasu (a więc kosztuje tyle). Dla uproszczenia, Załóżmy, że nie wiemy, czym jest f, ale załóżmy, że jest to albo 0.1, 0.2, 0.3,... 0.9, 1.0, a wcześniejsze prawdopodobieństwo każdej z tych możliwości wynosi 0,1, więc wszystkie te koszty są równie prawdopodobne a-priori.
Przypuśćmy, że pobieramy tylko 2 próbki stosu i widzimy instrukcję I na obu próbkach, oznaczoną obserwacją o=2/2. To daje nam nowe szacunki częstotliwości f z I, zgodnie z tym:
Prior
P(f=x) x P(o=2/2|f=x) P(o=2/2&&f=x) P(o=2/2&&f >= x) P(f >= x | o=2/2)
0.1 1 1 0.1 0.1 0.25974026
0.1 0.9 0.81 0.081 0.181 0.47012987
0.1 0.8 0.64 0.064 0.245 0.636363636
0.1 0.7 0.49 0.049 0.294 0.763636364
0.1 0.6 0.36 0.036 0.33 0.857142857
0.1 0.5 0.25 0.025 0.355 0.922077922
0.1 0.4 0.16 0.016 0.371 0.963636364
0.1 0.3 0.09 0.009 0.38 0.987012987
0.1 0.2 0.04 0.004 0.384 0.997402597
0.1 0.1 0.01 0.001 0.385 1
P(o=2/2) 0.385
Ostatnia kolumna mówi, że, na przykład, prawdopodobieństwo, że f > = 0.5 wynosi 92%, w porównaniu z wcześniejszym założeniem 60%.
Załóżmy, że przed założenia są różne. Załóżmy, że P(f=0.1) jest .991 (prawie pewne), a wszystkie inne możliwości są prawie niemożliwe (0,001). Innymi słowy, nasza poprzednia pewność jest taka, że I jest tania. Następnie otrzymujemy:
Prior
P(f=x) x P(o=2/2|f=x) P(o=2/2&& f=x) P(o=2/2&&f >= x) P(f >= x | o=2/2)
0.001 1 1 0.001 0.001 0.072727273
0.001 0.9 0.81 0.00081 0.00181 0.131636364
0.001 0.8 0.64 0.00064 0.00245 0.178181818
0.001 0.7 0.49 0.00049 0.00294 0.213818182
0.001 0.6 0.36 0.00036 0.0033 0.24
0.001 0.5 0.25 0.00025 0.00355 0.258181818
0.001 0.4 0.16 0.00016 0.00371 0.269818182
0.001 0.3 0.09 0.00009 0.0038 0.276363636
0.001 0.2 0.04 0.00004 0.00384 0.279272727
0.991 0.1 0.01 0.00991 0.01375 1
P(o=2/2) 0.01375
Teraz jest napisane P(f >= 0.5) jest 26%, w górę od poprzedniego założenia 0.6%. Tak więc Bayes pozwala nam zaktualizować nasze oszacowanie prawdopodobnego kosztu I. Jeśli ilość danych jest niewielka, nie mówi nam dokładnie, jaki jest koszt, tylko, że jest wystarczająco duży, aby być wart naprawiam.
Jeszcze inny sposób patrzenia na to jest nazywany reguła sukcesji .
Jeśli rzucisz monetą 2 razy, a wyskakuje Orzeł za każdym razem, co to mówi o prawdopodobnej wadze monety?
Można powiedzieć, że jest to dystrybucja Beta o średniej wartości (number of hits + 1) / (number of tries + 2) = (2+1)/(2+2) = 75%.
(kluczem jest to, że widzimy I więcej niż raz. Jeśli zobaczymy go tylko raz, to niewiele nam to mówi poza tym, że f > 0.)
Więc nawet bardzo mała liczba próbki mogą nam wiele powiedzieć o kosztach instrukcji, które widzi. (I zobaczy je z częstotliwością, średnio, proporcjonalną do ich kosztów. Jeśli n próbki zostaną pobrane, a f jest kosztem, to I pojawi się na próbkach nf+/-sqrt(nf(1-f)). Przykład, n=10, f=0.3, to są 3+/-1.4 próbki.)
Dodano : aby dać intuicyjne wyczucie różnicy między pomiarem a losowym próbkowaniem stosu:
Są teraz profilery, które próbkują stos, nawet na zegar ścienny czas, ale to, co wychodzi {[32] } to pomiary (lub gorąca ścieżka, lub hot spot, z którego "wąskie gardło" może łatwo ukryć). To, czego Ci nie pokazują (i łatwo mogą), to same rzeczywiste próbki. A jeśli twoim celem jest znaleźć wąskie gardło, ich liczba, którą musisz zobaczyć, to średnio, 2 podzielone przez ułamek czasu, który zajmuje.
Więc jeśli zajmie to 30% czasu, 2/.3 = średnio 6,7 próbek to pokaże, a szansa, że 20 próbek to pokaże, jest 99.2%.
Oto ilustracja off-the-cuff różnicy między badaniem pomiarów i badania próbek stosu. Wąskim gardłem może być jedna wielka plama, jak ta, lub wiele małych, to nie robi różnicy.

Pomiar jest poziomy; mówi ci, jaki ułamek czasu zajmują określone procedury. Próbkowanie jest pionowe. Jeśli jest jakiś sposób, aby uniknąć tego, co cały program robi w tym momencie, i jeśli widzisz to na sekundę próbka , znalazłeś wąskie gardło. To jest to, co robi różnicę - widząc cały powód spędzonego czasu, a nie tylko ile.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-05-30 12:09:44
Możesz użyć Valgrind z następującymi opcjami
valgrind --tool=callgrind ./(Your binary)
Wygeneruje plik o nazwie callgrind.out.x. Następnie możesz użyć narzędzia kcachegrind, aby odczytać ten plik. To daje graficzną analizę rzeczy z wynikami, takimi jak które linie kosztują ile.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-09-05 10:25:42
Zakładam, że używasz GCC. Standardowym rozwiązaniem byłoby profilowanie za pomocą gprof .
Pamiętaj, aby dodać -pg do kompilacji przed profilowaniem:
cc -o myprog myprog.c utils.c -g -pg
Jeszcze nie próbowałem, ale słyszałem dobre rzeczy o google-perftools . Zdecydowanie warto spróbować.
Powiązane pytanie tutaj .
Kilka innych buzzwords, jeśli gprof nie zrobi to za Ciebie: Valgrind , Intel VTune , Sun DTrace .
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-08-12 17:35:44
Nowsze jądra (np. najnowsze jądra Ubuntu) zawierają nowe narzędzia 'perf' (apt-get install linux-tools) AKA perf_events .
Są one wyposażone w Klasyczne profilery próbkowania (man-page) oraz niesamowity timechart!
Ważne jest to, że narzędzia te mogą być profilowaniem systemu , a nie tylko profilowaniem procesów - mogą pokazywać interakcje między wątkami, procesami i jądrem i pozwalają zrozumieć zależności między planowaniem i we/wy procesy.
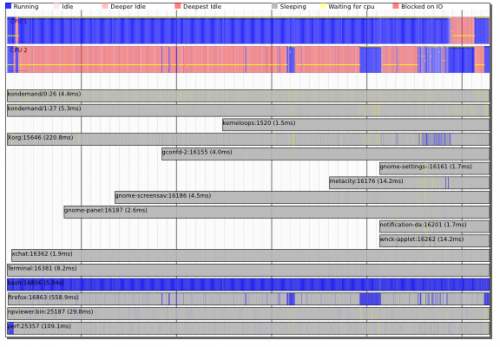
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-08-12 17:30:25
Użyłbym Valgrind i Callgrind jako podstawy dla mojego zestawu narzędzi do profilowania. Ważne jest, aby wiedzieć, że Valgrind jest w zasadzie maszyną wirtualną:
(wikipedia) Valgrind jest w istocie wirtualnym maszyna wykorzystująca just-in-time (JIT) techniki kompilacji, w tym dynamiczna rekompilacja. Nic z oryginalny program kiedykolwiek zostanie uruchomiony bezpośrednio na procesorze hosta. Zamiast tego Valgrind tłumaczy najpierw program do tymczasowej, prostszej formy called Kariera Reprezentacyjna (IR), który jest neutralny dla procesora, Forma oparta na SSA. Po konwersji, narzędzie (patrz poniżej) jest bezpłatne dowolne przekształcenia, jakie by chciały na IR, zanim valgrind przetłumaczy IR z powrotem do kodu maszynowego i pozwala uruchamia go procesor hosta.
Callgrind jest profilerem zbudowanym na tym. Główną korzyścią jest to, że nie trzeba uruchamiać aplikacji przez wiele godzin, aby uzyskać wiarygodne wyniki. Nawet jedna sekunda biegu wystarczy, aby uzyskać solidną, niezawodne wyniki, ponieważ Callgrind jest profilerem nie sondującym .
Innym narzędziem zbudowanym na Valgrind jest Massif. Używam go do profilowania wykorzystania pamięci sterty. Działa świetnie. To, co robi, to to, że daje migawki zużycia pamięci -- szczegółowe informacje, co trzyma jaki procent pamięci, i kto je tam umieścił. Informacje takie są dostępne w różnych momentach uruchomienia aplikacji.
Odpowiedź na uruchomienie valgrind --tool=callgrind nie jest kompletna bez pewnych opcji. Zwykle nie chcemy profilować 10 minut wolnego czasu uruchamiania pod Valgrind i chcemy profilować nasz program, gdy wykonuje jakieś zadanie.
valgrind --tool=callgrind --dump-instr=yes -v --instr-atstart=no ./binary > tmp
Teraz kiedy to działa i chcemy zacząć profilować powinniśmy uruchomić w innym oknie:
callgrind_control -i on
callgrind_control -k
Teraz mamy niektóre pliki o nazwie callgrind.Wynocha.* w bieżącym katalogu. Aby zobaczyć wyniki profilowania użyj:
kcachegrind callgrind.out.*
Polecam w następnym oknie kliknąć na nagłówek kolumny "Self", w przeciwnym razie pokazuje, że" main () " jest najbardziej czasochłonnym zadaniem. "Self" pokazuje, ile każda sama funkcja zajmowała czas, a nie razem z zależnymi.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-09-05 10:44:39
Jest to odpowiedź na odpowiedź Nazgoba Gprof .
Używam Gprof od kilku dni i znalazłem już trzy znaczące ograniczenia, z których jednego nie widziałem nigdzie indziej (jeszcze):
Nie działa poprawnie na kodzie wielowątkowym, chyba że użyjesz obejścia
Wykres wywołania jest mylony przez Wskaźniki funkcji. Przykład: mam funkcję o nazwie
multithread(), która pozwala mi na wielowątkowe a podanej funkcji nad podaną tablicą (obie przekazywane jako argumenty). Gprof postrzega jednak wszystkie wywołaniamultithread()jako równoważne dla celów obliczania czasu spędzonego u dzieci. Ponieważ niektóre funkcje, które przekazujęmultithread(), trwają znacznie dłużej niż inne, moje wykresy połączeń są w większości bezużyteczne. (Dla tych, którzy zastanawiają się, czy wątek jest tutaj problemem: nie,multithread()może opcjonalnie, i w tym przypadku, uruchomić wszystko sekwencyjnie tylko na wywołującym wątku).Tu jest napisane , że"... na liczby wywołań są uzyskiwane przez liczenie, a nie pobieranie próbek. Są całkowicie dokładne...". Jednak mój wykres połączeń daje mi 5345859132+784984078 jako statystyki połączeń do mojej najczęściej wywoływanej funkcji, gdzie pierwszy numer ma być wywołaniem bezpośrednim, a drugi rekurencyjnym (które są wszystkie od siebie). Ponieważ sugerowało to, że mam błąd, włożyłem długie (64-bitowe) liczniki do kodu i zrobiłem to samo ponownie. Moje liczniki: 5345859132 bezpośrednie i 78094395406 wywołań samo rekurencyjnych. Istnieją dużo tam cyfr, więc zwrócę uwagę, że wywołania rekurencyjne, które mierzę, to 78bn, w porównaniu z 784m z Gprof: współczynnik 100 różnych. Obie wersje były jednowątkowe i nieoptymalizowane, jedna skompilowana
-g, a druga-pg.
To był GNU Gprof (GNU Binutils for Debian) 2.18.0.20080103 działający pod 64-bitowym Debian Lenny, jeśli to komuś pomoże.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-09-15 09:33:33
Użyj Valgrind, callgrind i kcachegrind:
valgrind --tool=callgrind ./(Your binary)
Generuje callgrind.Wynocha.X. przeczytaj go używając kcachegrind.
Użyj gprof (add-pg):
cc -o myprog myprog.c utils.c -g -pg
(niezbyt dobre dla wielu wątków, wskaźników funkcji)
Użyj google-perftools:
Wykorzystuje próbkowanie czasu, ujawniają się wąskie gardła we / wy i procesora.
Intel VTune jest najlepszy (darmowy do celów edukacyjnych).
Inne: AMD Codeanalyst (od zastąpienia z AMD CodeXL), oprofile, 'perf' tools (apt-get install linux-tools)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-09-06 16:45:37
Analiza technik profilowania C++: gprof vs valgrind vs perf vs gperftools
W tej odpowiedzi użyję kilku różnych narzędzi do analizy kilku bardzo prostych programów testowych, aby konkretnie porównać, jak te narzędzia działają.
Poniższy program testowy jest bardzo prosty i wykonuje następujące czynności:
-
mainwywołaniafastimaybe_slow3 razy, jedno z wywołańmaybe_slowjest powolnePowolne wywołanie
maybe_slowjest 10x dłuższy i dominuje runtime, jeśli weźmiemy pod uwagę wywołania funkcji potomnejcommon. Idealnie, narzędzie profilujące będzie w stanie wskazać nam konkretne powolne wywołanie. -
Zarówno
fastjak imaybe_slowwywołaniecommon, które odpowiada za większość wykonania programu -
Interfejs programu to:
./main.out [n [seed]]I program wykonuje
O(n^2)pętle w sumie.seedjest po prostu uzyskanie innego wyjścia bez wpływu runtime.
Main.c
#include <inttypes.h>
#include <stdio.h>
#include <stdlib.h>
uint64_t __attribute__ ((noinline)) common(uint64_t n, uint64_t seed) {
for (uint64_t i = 0; i < n; ++i) {
seed = (seed * seed) - (3 * seed) + 1;
}
return seed;
}
uint64_t __attribute__ ((noinline)) fast(uint64_t n, uint64_t seed) {
uint64_t max = (n / 10) + 1;
for (uint64_t i = 0; i < max; ++i) {
seed = common(n, (seed * seed) - (3 * seed) + 1);
}
return seed;
}
uint64_t __attribute__ ((noinline)) maybe_slow(uint64_t n, uint64_t seed, int is_slow) {
uint64_t max = n;
if (is_slow) {
max *= 10;
}
for (uint64_t i = 0; i < max; ++i) {
seed = common(n, (seed * seed) - (3 * seed) + 1);
}
return seed;
}
int main(int argc, char **argv) {
uint64_t n, seed;
if (argc > 1) {
n = strtoll(argv[1], NULL, 0);
} else {
n = 1;
}
if (argc > 2) {
seed = strtoll(argv[2], NULL, 0);
} else {
seed = 0;
}
seed += maybe_slow(n, seed, 0);
seed += fast(n, seed);
seed += maybe_slow(n, seed, 1);
seed += fast(n, seed);
seed += maybe_slow(n, seed, 0);
seed += fast(n, seed);
printf("%" PRIX64 "\n", seed);
return EXIT_SUCCESS;
}
Gprof
[107]}Gprof wymaga rekompilacji oprogramowania z oprzyrządowaniem, a także wykorzystuje podejście próbkowania wraz z tym oprzyrządowaniem. Dlatego zachowuje równowagę między dokładnością (próbkowanie nie zawsze jest w pełni dokładne i może pominąć funkcje) a spowolnieniem wykonania (oprzyrządowanie i próbkowanie są stosunkowo szybkimi technikami, które nie spowalniają wykonania bardzo).Gprof jest wbudowany w GCC / binutils, więc wszystko, co musimy zrobić, to skompilować z opcją -pg, aby włączyć gprof. Następnie uruchamiamy program normalnie z parametrem size CLI, który powoduje uruchomienie rozsądnego czasu trwania kilku sekund (10000):
gcc -pg -ggdb3 -O3 -std=c99 -Wall -Wextra -pedantic -o main.out main.c
time ./main.out 10000
Ze względów edukacyjnych wykonamy również bieg bez włączonej optymalizacji. Zauważ, że jest to bezużyteczne w praktyce, ponieważ zwykle zależy Ci tylko na optymalizacji wydajności zoptymalizowanego programu:
gcc -pg -ggdb3 -O0 -std=c99 -Wall -Wextra -pedantic -o main.out main.c
./main.out 10000
Po pierwsze, time mówi nam, że czas wykonania z i bez -pg były takie same, co jest świetne: bez spowolnienia! Jednak widziałem konta 2x - 3x spowolnienia na złożonym oprogramowaniu, np. jak pokazano w tym bilecie.
Ponieważ skompilowaliśmy z -pg, uruchomienie programu tworzy plik gmon.out zawierający dane profilujące.
Możemy zauważyć, że plik graficznie z gprof2dot, jak zapytano w: czy możliwe jest uzyskanie graficznej reprezentacji gprof wyniki?
sudo apt install graphviz
python3 -m pip install --user gprof2dot
gprof main.out > main.gprof
gprof2dot < main.gprof | dot -Tsvg -o output.svg
Tutaj, narzędzie gprof odczytuje gmon.out Informacje o śledzeniu i generuje czytelny dla człowieka raport w main.gprof, który gprof2dot odczytuje, aby wygenerować wykres.
Źródło gprof2dot znajduje się pod adresem: https://github.com/jrfonseca/gprof2dot
Obserwujemy następujący przebieg-O0:

I dla -O3 run:

Wyjście -O0 jest ładne wiele wyjaśnień. Na przykład, pokazuje, że 3 wywołania maybe_slow i ich wywołania potomne zajmują 97,56% całkowitego czasu wykonania, chociaż samo wykonanie maybe_slow bez dzieci stanowi 0,00% całkowitego czasu wykonania, tzn. prawie cały czas spędzony w tej funkcji był spędzony na wywołaniach potomnych.
Do zrobienia: dlaczego main brakuje na wyjściu -O3, mimo że widzę to na bt W GDB? Brak funkcji z wyjścia GProf myślę, że to dlatego, że gprof jest również pobieranie próbek w oparciu o jego skompilowane oprzyrządowanie, a -O3 main jest po prostu zbyt szybki i nie ma próbek.
Wybieram wyjście SVG zamiast PNG, ponieważ SVG można przeszukiwać za pomocą Ctrl + F, A Rozmiar pliku może być około 10x mniejszy. Ponadto, szerokość i wysokość wygenerowanego obrazu może być humoungoous z dziesiątkami tysięcy pikseli dla złożonego oprogramowania, i GNOME eog 3.28.1 błędy w tym przypadku dla PNGs, podczas gdy SVGs są otwierane przez moją przeglądarkę automatycznie. gimp 2.8 działa jednak dobrze, Zobacz też:
- https://askubuntu.com/questions/1112641/how-to-view-extremely-large-images
- https://unix.stackexchange.com/questions/77968/viewing-large-image-on-linux
- https://superuser.com/questions/356038/viewer-for-huge-images-under-linux-100-mp-color-images
Ale nawet wtedy będziesz dużo przeciągał obraz, aby znaleźć to, co chcesz, zobacz np. Ten obraz z przykład" prawdziwego " oprogramowania zaczerpnięty z tego biletu :

Czy możesz łatwo znaleźć najbardziej krytyczny stos połączeń z tymi wszystkimi malutkimi, niesortowanymi liniami spaghetti przechodzącymi między sobą? Być może są lepsze opcje dot jestem pewien, ale nie chcę tam teraz iść. To, czego naprawdę potrzebujemy, to odpowiednia dedykowana przeglądarka, ale jeszcze nie znalazłem: {]}
Możesz jednak użyć mapy kolorów, aby nieco złagodzić te problemy. Na przykład, na poprzednim ogromnym obrazie, w końcu udało mi się znaleźć ścieżkę krytyczną po lewej stronie, kiedy dokonałem genialnej dedukcji, że zielony pojawia się po czerwonym, a następnie w końcu ciemniejszy i ciemniejszy niebieski.
Alternatywnie, możemy również obserwować wyjście tekstowe wbudowanego narzędzia binutilsgprof, które wcześniej zapisaliśmy w:
cat main.gprof
Domyślnie, daje to bardzo obszerne wyjście, które wyjaśnia, co oznaczają dane wyjściowe. Ponieważ nie potrafię tego lepiej wyjaśnić, pozwolę ci to przeczytać samemu.
Po zapoznaniu się z formatem wyjściowym danych, możesz zmniejszyć szczegółowość, aby wyświetlać tylko dane bez samouczka za pomocą opcji -b:
gprof -b main.out
W naszym przykładzie wyjścia były dla -O0:
Flat profile:
Each sample counts as 0.01 seconds.
% cumulative self self total
time seconds seconds calls s/call s/call name
100.35 3.67 3.67 123003 0.00 0.00 common
0.00 3.67 0.00 3 0.00 0.03 fast
0.00 3.67 0.00 3 0.00 1.19 maybe_slow
Call graph
granularity: each sample hit covers 2 byte(s) for 0.27% of 3.67 seconds
index % time self children called name
0.09 0.00 3003/123003 fast [4]
3.58 0.00 120000/123003 maybe_slow [3]
[1] 100.0 3.67 0.00 123003 common [1]
-----------------------------------------------
<spontaneous>
[2] 100.0 0.00 3.67 main [2]
0.00 3.58 3/3 maybe_slow [3]
0.00 0.09 3/3 fast [4]
-----------------------------------------------
0.00 3.58 3/3 main [2]
[3] 97.6 0.00 3.58 3 maybe_slow [3]
3.58 0.00 120000/123003 common [1]
-----------------------------------------------
0.00 0.09 3/3 main [2]
[4] 2.4 0.00 0.09 3 fast [4]
0.09 0.00 3003/123003 common [1]
-----------------------------------------------
Index by function name
[1] common [4] fast [3] maybe_slow
I dla -O3:
Flat profile:
Each sample counts as 0.01 seconds.
% cumulative self self total
time seconds seconds calls us/call us/call name
100.52 1.84 1.84 123003 14.96 14.96 common
Call graph
granularity: each sample hit covers 2 byte(s) for 0.54% of 1.84 seconds
index % time self children called name
0.04 0.00 3003/123003 fast [3]
1.79 0.00 120000/123003 maybe_slow [2]
[1] 100.0 1.84 0.00 123003 common [1]
-----------------------------------------------
<spontaneous>
[2] 97.6 0.00 1.79 maybe_slow [2]
1.79 0.00 120000/123003 common [1]
-----------------------------------------------
<spontaneous>
[3] 2.4 0.00 0.04 fast [3]
0.04 0.00 3003/123003 common [1]
-----------------------------------------------
Index by function name
[1] common
Jako bardzo szybkie podsumowanie dla każdego odcinka np.:
0.00 3.58 3/3 main [2]
[3] 97.6 0.00 3.58 3 maybe_slow [3]
3.58 0.00 120000/123003 common [1]
Skupia się wokół funkcji, która pozostaje wcięta (maybe_flow). [3] jest ID tej funkcji. Powyżej funkcji znajdują się jej wywoływacze, a poniżej wywoływacze.
Dla -O3, zobacz tutaj, jak w wyjściu graficznym, które maybe_slow i fast nie mają znanego rodzica, co oznacza dokumentacja <spontaneous>.
Nie jestem pewien, czy jest dobry sposób na profilowanie linii po linii za pomocą gprof: `gprof ' czas spędzony w poszczególnych liniach kod
Valgrind callgrind
Valgrind uruchamia program poprzez maszynę wirtualną valgrind. To sprawia, że profilowanie jest bardzo dokładne, ale również powoduje bardzo duże spowolnienie programu. Kcachegrind został stworzony z myślą o osobach, które chcą się rozwijać i rozwijać.]}
Callgrind to narzędzie valgrind do profilowania kodu, a kcachegrind to program KDE, który może wizualizować cachegrind wyjście.
Najpierw musimy usunąć flagę -pg, aby wrócić do normalnej kompilacji, w przeciwnym razie uruchomienie nie powiedzie się z Profiling timer expired, i tak, to jest tak powszechne, że zrobiłem i było pytanie o przepełnienie stosu.
Więc kompilujemy i uruchamiamy jako:
sudo apt install kcachegrind valgrind
gcc -ggdb3 -O3 -std=c99 -Wall -Wextra -pedantic -o main.out main.c
time valgrind --tool=callgrind valgrind --dump-instr=yes \
--collect-jumps=yes ./main.out 10000
Włączam --dump-instr=yes --collect-jumps=yes, ponieważ to również wyrzuca informacje, które pozwalają nam zobaczyć podział wydajności na linię montażową, przy stosunkowo niewielkich kosztach dodatkowych.
Off the bat, time mówi nam, że wykonanie programu zajęło 29,5 sekundy, więc na tym przykładzie mieliśmy spowolnienie około 15x. Oczywiście to spowolnienie będzie poważnym ograniczeniem dla większych obciążeń. Na" przykładzie oprogramowania w świecie rzeczywistym " wspomnianym tutaj, zaobserwowałem spowolnienie 80x.
Run generuje plik z danymi profilu o nazwie callgrind.out.<pid> np. callgrind.out.8554 W moim przypadku. Oglądamy ten plik za pomocą:
kcachegrind callgrind.out.8554
Który pokazuje GUI, który zawiera dane podobne do tekstowego gprof wyjście:

Również, jeśli wejdziemy na zakładkę "Call Graph" w prawym dolnym rogu, zobaczymy Wykres wywołania, który możemy wyeksportować klikając go prawym przyciskiem myszy, aby uzyskać następujący obraz z nieuzasadnionymi ilościami białej obramowania: -)

Myślę, że fast nie pokazuje się na tym wykresie, ponieważ kcachegrind musiał uprościć wizualizację, ponieważ to wywołanie zajmuje zbyt mało czasu, prawdopodobnie będzie to zachowanie, które chcesz na prawdziwym program. Menu kliknij prawym przyciskiem myszy ma pewne ustawienia, aby kontrolować, kiedy cull takie węzły, ale nie mogłem go pokazać tak krótkie połączenie po szybkiej próbie. Jeśli kliknę na {[24] } w lewym oknie, wyświetli się Wykres wywołania z fast, więc stos został przechwycony. Nikt jeszcze nie znalazł sposobu na wyświetlenie pełnego wykresu wywołania wykresu: Make callgrind Pokaż wszystkie wywołania funkcji w kcachegrind callgraph
TODO na skomplikowanym oprogramowaniu C++, widzę kilka wpisów typu <cycle N>, na przykład <cycle 11> gdzie oczekiwałbym nazw funkcji, co to znaczy? Zauważyłem, że jest przycisk "wykrywanie cyklu", który włącza i wyłącza, ale co to oznacza?
perf od linux-tools
perf wydaje się, że używa wyłącznie mechanizmów próbkowania jądra Linuksa. To sprawia, że konfiguracja jest bardzo prosta, ale nie do końca dokładna.
sudo apt install linux-tools
time perf record -g ./main.out 10000
To dodało 0,2 s do wykonania, więc pod względem czasu jesteśmy w porządku, ale nadal nie widzę większego zainteresowania po rozszerzeniu common węzeł ze strzałką w prawo na klawiaturze:
Samples: 7K of event 'cycles:uppp', Event count (approx.): 6228527608
Children Self Command Shared Object Symbol
- 99.98% 99.88% main.out main.out [.] common
common
0.11% 0.11% main.out [kernel] [k] 0xffffffff8a6009e7
0.01% 0.01% main.out [kernel] [k] 0xffffffff8a600158
0.01% 0.00% main.out [unknown] [k] 0x0000000000000040
0.01% 0.00% main.out ld-2.27.so [.] _dl_sysdep_start
0.01% 0.00% main.out ld-2.27.so [.] dl_main
0.01% 0.00% main.out ld-2.27.so [.] mprotect
0.01% 0.00% main.out ld-2.27.so [.] _dl_map_object
0.01% 0.00% main.out ld-2.27.so [.] _xstat
0.00% 0.00% main.out ld-2.27.so [.] __GI___tunables_init
0.00% 0.00% main.out [unknown] [.] 0x2f3d4f4944555453
0.00% 0.00% main.out [unknown] [.] 0x00007fff3cfc57ac
0.00% 0.00% main.out ld-2.27.so [.] _start
Więc potem próbuję porównać program -O0, aby zobaczyć, czy to coś pokazuje, i dopiero teraz, w końcu, widzę Wykres wywołania:
Samples: 15K of event 'cycles:uppp', Event count (approx.): 12438962281
Children Self Command Shared Object Symbol
+ 99.99% 0.00% main.out [unknown] [.] 0x04be258d4c544155
+ 99.99% 0.00% main.out libc-2.27.so [.] __libc_start_main
- 99.99% 0.00% main.out main.out [.] main
- main
- 97.54% maybe_slow
common
- 2.45% fast
common
+ 99.96% 99.85% main.out main.out [.] common
+ 97.54% 0.03% main.out main.out [.] maybe_slow
+ 2.45% 0.00% main.out main.out [.] fast
0.11% 0.11% main.out [kernel] [k] 0xffffffff8a6009e7
0.00% 0.00% main.out [unknown] [k] 0x0000000000000040
0.00% 0.00% main.out ld-2.27.so [.] _dl_sysdep_start
0.00% 0.00% main.out ld-2.27.so [.] dl_main
0.00% 0.00% main.out ld-2.27.so [.] _dl_lookup_symbol_x
0.00% 0.00% main.out [kernel] [k] 0xffffffff8a600158
0.00% 0.00% main.out ld-2.27.so [.] mmap64
0.00% 0.00% main.out ld-2.27.so [.] _dl_map_object
0.00% 0.00% main.out ld-2.27.so [.] __GI___tunables_init
0.00% 0.00% main.out [unknown] [.] 0x552e53555f6e653d
0.00% 0.00% main.out [unknown] [.] 0x00007ffe1cf20fdb
0.00% 0.00% main.out ld-2.27.so [.] _start
maybe_slow i fast były zbyt szybkie i nie dostały żadnych próbek? Czy działa dobrze z -O3 na większych programach, których wykonanie zajmuje więcej czasu? Przegapiłem jakąś opcję CLI? Dowiedziałem się o -F aby kontrolować częstotliwość próbkowania w Hertz, ale podkręciłem go do max dozwolonego domyślnie -F 39500 (można zwiększyć o sudo) i nadal nie widzę czystych połączeń.
Jedną z fajnych rzeczy perf jest narzędzie FlameGraph od Brendana Gregga, które wyświetla timingi stosu połączeń w bardzo schludny sposób, który pozwala szybko zobaczyć duże połączenia. Narzędzie jest dostępne pod adresem: https://github.com/brendangregg/FlameGraph i jest również wspomniany w swoim samouczku perf na: http://www.brendangregg.com/perf.html#FlameGraphs kiedy biegłem perf bez sudo dostałem ERROR: No stack counts found więc na razie będę to robił z sudo:
git clone https://github.com/brendangregg/FlameGraph
sudo perf record -F 99 -g -o perf_with_stack.data ./main.out 10000
sudo perf script -i perf_with_stack.data | FlameGraph/stackcollapse-perf.pl | FlameGraph/flamegraph.pl > flamegraph.svg
Ale w tak prostym programie wyjście nie jest zbyt łatwe do zrozumienia, ponieważ nie możemy łatwo zobaczyć ani maybe_slow, ani fast na tym wykresie:

Na bardziej złożonym przykładzie staje się jasne, co oznacza Wykres:

TODO istnieje dziennik [unknown] funkcji w tym przykładzie, dlaczego tak jest?
Inne Interfejsy perf GUI, które mogą być tego warte, to:
-
Eclipse Trace Compass plugin: https://www.eclipse.org/tracecompass/
Ale ma to tę zaletę, że musisz najpierw przekonwertować dane do wspólnego formatu śledzenia, co można zrobić za pomocą
perf data --to-ctf, ale musi być włączony w czasie kompilacji / mieć {78]} wystarczająco nowy, z których oba nie są w przypadku perf w Ubuntu 18.04 -
Https://github.com/KDAB/hotspot
Minusem tego jest to, że wydaje się, że nie ma pakietu Ubuntu, a jego budowa wymaga Qt 5.10, podczas gdy Ubuntu 18.04 jest w Qt 5.9.
Gperftools
Wcześniej nazywany "Google Performance Tools", źródło: https://github.com/gperftools/gperftools na podstawie próbki.
Najpierw zainstaluj gperftools z:
sudo apt install google-perftools
Następnie możemy włączyć Profiler procesora gperftools na dwa sposoby: w czasie wykonywania lub w czasie kompilacji.
W trybie runtime musimy przekazać set LD_PRELOAD, aby wskazać libprofiler.so, które można znaleźć za pomocą locate libprofiler.so, np. w moim systemie:
gcc -ggdb3 -O3 -std=c99 -Wall -Wextra -pedantic -o main.out main.c
LD_PRELOAD=/usr/lib/x86_64-linux-gnu/libprofiler.so \
CPUPROFILE=prof.out ./main.out 10000
gcc -Wl,--no-as-needed,-lprofiler,--as-needed -ggdb3 -O3 -std=c99 -Wall -Wextra -pedantic -o main.out main.c
CPUPROFILE=prof.out ./main.out 10000
Zobacz także: gperftools - plik profilu nie wyrzucany
Najładniejszy sposób przeglądania tych danych Do tej pory okazało się, że wyjście pprof w tym samym formacie, który kcachegrind przyjmuje jako Wejście (Tak, narzędzie Valgrind-project-viewer-tool) i użyć kcachegrind, aby wyświetlić, że:
google-pprof --callgrind main.out prof.out > callgrind.out
kcachegrind callgrind.out
Po uruchomieniu jednej z tych metod, otrzymujemy plik danych profilu prof.out jako wyjście. Plik ten może być wyświetlany graficznie w formacie SVG w następujący sposób:
google-pprof --web main.out prof.out

Który daje jako znany Wykres wywołania, podobnie jak inne narzędzia, ale z niezgrabną jednostką liczby próbek, a nie sekund.
Alternatywnie, możemy również uzyskać niektóre dane tekstowe za pomocą:
google-pprof --text main.out prof.out
Co daje:
Using local file main.out.
Using local file prof.out.
Total: 187 samples
187 100.0% 100.0% 187 100.0% common
0 0.0% 100.0% 187 100.0% __libc_start_main
0 0.0% 100.0% 187 100.0% _start
0 0.0% 100.0% 4 2.1% fast
0 0.0% 100.0% 187 100.0% main
0 0.0% 100.0% 183 97.9% maybe_slow
Zobacz także: Jak korzystać z narzędzi Google perf
Instrument kodu z raw perf_event_open syscalls
Myślę, że jest to ten sam podstawowy podsystem, którego używa perf, ale oczywiście możesz osiągnąć jeszcze większą kontrolę poprzez jawne oprzyrządowanie swojego programu w czasie kompilacji z interesującymi zdarzeniami.
To jest be zbyt hardcore dla większości ludzi, ale to trochę zabawne. Minimal runnable example at: szybki sposób zliczenia liczby instrukcji wykonanych w programie C
Testowane w Ubuntu 18.04, gprof2dot 2019.11.30, valgrind 3.13.0, perf 4.15.18, Linux kernel 4.15.0, FLameGraph 1a0dc6985aad06e76857cf2a354bd5ba0c9ce96b, gperftools 2.5-2.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-11-18 16:30:15
Do programów jednowątkowych można użyć igprof , The Ignominous Profiler: https://igprof.org /.
Jest to Profiler próbkowania, wzdłuż linii.. długa... odpowiedź Mike 'a Dunlavey' a, która będzie prezentować wyniki w przeglądalnym drzewie stosów wywołań, z adnotacją o czasie lub pamięci spędzonej w każdej funkcji, kumulatywnej lub przypadającej na funkcję.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-03-17 12:20:45
Warto również wspomnieć
- HPCToolkit (http://hpctoolkit.org/) - Open-source, działa dla programów równoległych i ma GUI, z którym można spojrzeć na wyniki na wiele sposobów
- Intel VTune ( https://software.intel.com/en-us/vtune ) - Jeśli masz Kompilatory Intela to jest bardzo dobre
- TAU ( http://www.cs.uoregon.edu/research/tau/home.php )
Używałem HPCToolkit i VTune i są bardzo skuteczne w znalezieniu długiej pole w namiocie i nie trzeba przekompilowywaä ‡ kodu (poza tym, Ĺźe trzeba uĹźyÄ ‡ - g-O lub RelWithDebInfo typu build w CMake aby uzyskaÄ ‡ sensowne wyjĹ " cie). Słyszałem, że TAU ma podobne możliwości.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2018-09-14 22:56:48
Są to dwie metody, których używam do przyspieszenia mojego kodu:
dla aplikacji związanych z procesorem:
- użyj profilera w trybie debugowania, aby zidentyfikować wątpliwe części kodu
- następnie przełącz się na tryb RELEASE i komentuj wątpliwe sekcje kodu (stubuj go bez niczego), dopóki nie zobaczysz zmian w wydajności.
dla aplikacji połączonych we/wy:
- użyj profilera w trybie RELEASE, aby zidentyfikować wątpliwe części Twojego kodu.
N. B.
Jeśli nie masz profilera, użyj profilera biedaka. Naciśnij pauza podczas debugowania aplikacji. Większość pakietów deweloperskich rozbije się na assembly z komentowanymi numerami linii. Statystycznie prawdopodobne jest, że wylądujesz w regionie, który zużywa większość cykli procesora.
Dla procesora powodem profilowania w trybie DEBUG jest to, że jeśli próbowałeś profilować w trybie RELEASE, kompilator będzie zmniejsz matematykę, wektoryzuj pętle i funkcje wbudowane, które powodują, że Twój kod staje się bałaganem, którego nie da się zmapować po złożeniu. bałagan nie do zmapowania oznacza, że Twój profiler nie będzie w stanie jednoznacznie zidentyfikować, co trwa tak długo, ponieważ zespół może nie odpowiadać kodowi źródłowemu pod optymalizacją . Jeśli potrzebujesz wydajności (np. wyczulonej na czas) trybu RELEASE, wyłącz funkcje debuggera w razie potrzeby, aby zachować użyteczną wydajność.
For I / O-bound, the profiler może nadal identyfikować operacje We/Wy w trybie RELEASE, ponieważ operacje We / Wy są albo zewnętrznie połączone ze współdzieloną biblioteką (przez większość czasu), albo w najgorszym przypadku, spowodują wektor przerwania wywołania sys (który jest również łatwo rozpoznawalny przez profiler).
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2015-09-05 23:35:51
Możesz użyć frameworka logowania jak loguru ponieważ zawiera znaczniki czasu i całkowity czas pracy, który można ładnie wykorzystać do profilowania:

Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2019-05-21 13:28:31
Możesz użyć biblioteki iprof:
Https://gitlab.com/Neurochrom/iprof
Https://github.com/Neurochrom/iprof
Jest wieloplatformowy i pozwala nie mierzyć wydajności aplikacji również w czasie rzeczywistym. Możesz nawet połączyć go z wykresem na żywo. Pełne zastrzeżenie: jestem autorem.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2019-02-24 18:01:00
W Pracy mamy naprawdę ładne narzędzie, które pomaga nam monitorować to, co chcemy w zakresie planowania. Było to przydatne wiele razy.
Jest w C++ i musi być dostosowany do Twoich potrzeb. Niestety nie mogę udostępniać kodu, tylko pojęcia.
Używasz bufora " large "volatile zawierającego znaczniki czasu i identyfikator zdarzenia, który możesz zrzucić po śmierci lub po zatrzymaniu systemu logowania (i zrzucić to na przykład do pliku).
Pobierasz tzw. duży bufor ze wszystkimi danymi mały interfejs przetwarza go i pokazuje zdarzenia z nazwą (góra/dół + wartość), tak jak oscyloskop robi to z kolorami (skonfigurowany w pliku .hpp).
Dostosowujesz ilość generowanych zdarzeń, aby skupić się wyłącznie na tym, czego pragniesz. Pomogło nam to w rozwiązywaniu problemów z planowaniem, zużywając żądaną ilość procesora na podstawie liczby rejestrowanych zdarzeń na sekundę.
Potrzebujesz 3 plików:
toolname.hpp // interface
toolname.cpp // code
tool_events_id.hpp // Events ID
Pojęciem jest definiowanie zdarzeń w tool_events_id.hpp w ten sposób:
// EVENT_NAME ID BEGIN_END BG_COLOR NAME
#define SOCK_PDU_RECV_D 0x0301 //@D00301 BGEEAAAA # TX_PDU_Recv
#define SOCK_PDU_RECV_F 0x0302 //@F00301 BGEEAAAA # TX_PDU_Recv
Ty zdefiniuj również kilka funkcji w toolname.hpp:
#define LOG_LEVEL_ERROR 0
#define LOG_LEVEL_WARN 1
// ...
void init(void);
void probe(id,payload);
// etc
Gdziekolwiek w kodzie możesz użyć :
toolname<LOG_LEVEL>::log(EVENT_NAME,VALUE);
Funkcja probe używa kilku linii montażowych, aby jak najszybciej pobrać znacznik czasu zegara, a następnie ustawia wpis w buforze. Mamy również przyrost atomowy, aby bezpiecznie znaleźć indeks, gdzie przechowywać Zdarzenie dziennika.
Oczywiście bufor jest okrągły.
Mam nadzieję, że pomysł nie jest zaciemniony przez brak przykładowego kodu.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2019-05-17 10:13:01
Właściwie trochę zaskoczony, nie wielu wspomniało o google / benchmark , podczas gdy jest to trochę kłopotliwe, aby przypinać konkretny obszar kodu, szczególnie jeśli baza kodu jest trochę duża, jednak uznałem to za bardzo pomocne, gdy jest używane w połączeniu z callgrind
IMHO identyfikacja elementu, który powoduje wąskie gardło, jest tutaj kluczem. Chciałbym jednak spróbować odpowiedzieć na następujące pytania najpierw i wybrać narzędzie na podstawie tego
- Czy mój algorytm jest poprawny ?
- czy są zamki, które udowadniają, że są szyjkami butelek ?
- czy jest jakiś konkretny fragment kodu, który okazuje się być winowajcą ?
- A może IO, obsługiwane i zoptymalizowane ?
valgrind Połączenie callrind i kcachegrind powinno zapewnić przyzwoitą ocenę w powyższych punktach, a gdy już ustalimy, że istnieją problemy z jakąś sekcją kodu, sugerowałbym, aby znak mikro ławki google benchmark był dobrym miejscem do rozpoczęcia.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2019-11-03 14:47:54
Użyj znacznika -pg podczas kompilacji i łączenia kodu i uruchom plik wykonywalny. Podczas wykonywania tego programu dane profilowania są zbierane w pliku a.out.
Istnieją dwa różne rodzaje profilowania
1-Profilowanie płaskie:
uruchamiając komendę gprog --flat-profile a.out otrzymujesz następujące dane
- jaki procent całkowitego czasu poświęcono na funkcję,
- ile sekund zostało spędzonych w funkcji-włączając i wyłączając wywołania do funkcji podrzędnych,
- numer of calls,
- średni czas na połączenie.
2 - profilowanie Wykresów
nam polecenie gprof --graph a.out, aby uzyskać następujące dane dla każdej funkcji, która zawiera
- W każdej sekcji jedna funkcja jest oznaczona numerem indeksu.
- Powyżej funkcji znajduje się lista funkcji, które wywołują funkcję .
- Poniżej funkcji znajduje się lista funkcji, które są wywoływane przez funkcję .
Aby uzyskać więcej informacji, możesz zajrzeć do https://sourceware.org/binutils/docs-2.32/gprof/
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2019-12-07 12:52:42
Użyj oprogramowania do debugowania jak rozpoznać, gdzie kod działa powoli ?
Po prostu pomyśl, że masz przeszkodę, gdy jesteś w ruchu, to zmniejszy to twoją prędkość
Jak to niechciane zapętlenie realokacji, przepełnienie bufora,wyszukiwanie,wycieki pamięci itp. operacje zużywają więcej mocy wykonawczej to wpłynie niekorzystnie na wydajność kodu, Przed profilowaniem należy dodać -pg do kompilacji:
g++ your_prg.cpp -pg LUB cc my_program.cpp -g -pg zgodnie z Twoim kompilator
Jeszcze nie próbowałem, ale słyszałem dobre rzeczy o google-perftools. Zdecydowanie warto spróbować.
valgrind --tool=callgrind ./(Your binary)
Wygeneruje plik o nazwie gmon.wyjdź albo zadzwoń.Wynocha.x. następnie możesz użyć kcachegrind lub debugger tool, aby odczytać ten plik. To daje graficzną analizę rzeczy z wynikami, takimi jak które linie kosztują ile.
Myślę, że tak
Jako, że nikt nie wspomniał o Arm MAP, dodałbym ją, ponieważ osobiście z powodzeniem używałem Map do profilowania programu naukowego C++.
Arm MAP jest profilerem dla równoległych, wielowątkowych lub jednowątkowych kodów C, C++, Fortran i F90. Zapewnia dogłębną analizę i wskazanie wąskich gardeł do linii źródłowej. W przeciwieństwie do większości profilerów, został zaprojektowany, aby móc profilować pthreads, OpenMP lub MPI dla kodu równoległego i gwintowanego.
MAP jest oprogramowaniem komercyjnym.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2019-06-28 04:44:24