Pandy101
- Jak wykonać (
INNER| (LEFT|RIGHT|FULL)OUTER)JOINz pand? - Jak dodać Nan dla brakujących wierszy po połączeniu?
- Jak pozbyć się NaNs po połączeniu?
- Czy Mogę połączyć się z indeksem?
- Jak połączyć wiele ramek danych? [[11]}Krzyż połączyć się z pand?
-
merge?join?concat?update? Kto? Co? Dlaczego?!
... i nie tylko. Widziałem te powtarzające się pytania pytające o różne aspekty pandy łączą funkcjonalność. Większość informacji dotyczących merge i jego różnych przypadków użycia jest dziś rozdrobniona na dziesiątki źle sformułowanych, niezbadanych postów. Celem jest zebranie kilku ważniejszych punktów dla potomności.
[[26]}ten QnA ma być kolejną odsłoną serii pomocnych poradników dla użytkowników na temat idiomów pand (zobacz ten post na pivoting i ten post na concatenation , który będę dotykał na, później).Proszę pamiętać, że ten post jest a nie miał być zamiennikiem dokumentacji , więc proszę przeczytać również to! Niektóre z przykładów są zaczerpnięte stamtąd.
Spis treści
dla ułatwienia dostępu.
5 answers
[62]} ten post ma na celu dać czytelnikom podkład na temat SQL-flavored Scalanie z pandy, jak go używać, a kiedy nie używać.
W szczególności, oto, przez co przejdzie ten post:
-
Podstawy-rodzaje złączy (LEWA, PRAWA, zewnętrzna, wewnętrzna)
- łączenie z różnymi nazwami kolumn
- łączenie z wieloma kolumnami
- unikanie zduplikowanej kolumny klawisza scalania na wyjściu
What this post (and other posts by me w tym wątku) nie przejdzie:
- dyskusje i terminy związane z wydajnością (na razie). Głównie godne uwagi wzmianki o lepszych alternatywach, w stosownych przypadkach.
- Obsługa przyrostków, usuwanie dodatkowych kolumn, zmiana nazw wyjść i inne szczególne przypadki użycia. Są inne (Czytaj: lepsze) posty, które zajmują się tym, więc wymyśl to!
Uwaga
Większość przykładów domyślnie wykonuje operacje łączenia wewnętrznego, demonstrując różne funkcje, o ile nie zaznaczono inaczej.Ponadto, wszystkie ramki danych tutaj mogą być kopiowane i replikowane tak możesz się nimi bawić. Zobacz też to post jak odczytywać ramki danych ze schowka.
Wreszcie, wszystkie wizualne reprezentacje operacji łączenia zostały ręcznie narysowane za pomocą rysunków Google. Inspiracja z tutaj .
Dość gadania, po prostu Pokaż mi jak używać merge!
Setup & Basics
np.random.seed(0)
left = pd.DataFrame({'key': ['A', 'B', 'C', 'D'], 'value': np.random.randn(4)})
right = pd.DataFrame({'key': ['B', 'D', 'E', 'F'], 'value': np.random.randn(4)})
left
key value
0 A 1.764052
1 B 0.400157
2 C 0.978738
3 D 2.240893
right
key value
0 B 1.867558
1 D -0.977278
2 E 0.950088
3 F -0.151357
Dla dobra z prostoty, kolumna klawiszy ma tę samą nazwę (na razie).
An wewnętrzne połączenie jest reprezentowane przez

Uwaga
To, wraz z nadchodzącymi liczbami, wszystkie są zgodne z tą konwencją:
- niebieski wskazuje wiersze, które są obecne w wyniku połączenia
- czerwony wskazuje wiersze, które są wykluczone z wyniku (tj. usunięte)
- zielony wskazuje brakujące wartości, które są zastępowane przez
NaNs w wyniku
Aby wykonać połączenie wewnętrzne, zadzwoń merge po lewej ramce danych, określając prawą ramkę danych i klucz join (przynajmniej) jako argumenty.
left.merge(right, on='key')
# Or, if you want to be explicit
# left.merge(right, on='key', how='inner')
key value_x value_y
0 B 0.400157 1.867558
1 D 2.240893 -0.977278
Zwraca tylko wiersze z left i right, które mają wspólny klucz (w tym przykładzie, "B" I "D).
A lewy zewnętrzny łącznik lub lewy łącznik jest reprezentowany przez

Można to wykonać przez podanie how='left'.
left.merge(right, on='key', how='left')
key value_x value_y
0 A 1.764052 NaN
1 B 0.400157 1.867558
2 C 0.978738 NaN
3 D 2.240893 -0.977278
Uwaga miejsce w klasyfikacji NaNs. Jeśli podasz how='left', to używane są tylko klucze z left, a brakujące dane z {[22] } są zastępowane przez NaN.
I podobnie, dla prawe złącze zewnętrzne , lub prawe złącze, które jest...

...podaj how='right':
left.merge(right, on='key', how='right')
key value_x value_y
0 B 0.400157 1.867558
1 D 2.240893 -0.977278
2 E NaN 0.950088
3 F NaN -0.151357
Tutaj używane są klucze z right, a brakujące dane z left są zastępowane przez NaN.
Wreszcie, dla pełnego połączenia zewnętrznego , podanego przez

Określić how='outer'.
left.merge(right, on='key', how='outer')
key value_x value_y
0 A 1.764052 NaN
1 B 0.400157 1.867558
2 C 0.978738 NaN
3 D 2.240893 -0.977278
4 E NaN 0.950088
5 F NaN -0.151357
To wykorzystuje klucze z obu ramek i Nan są wstawiane dla brakujących wierszy w obu.
Dokumentacja ładnie podsumowuje te różne połączenia:

Inne połączenia-lewo-wykluczające, prawo-wykluczające i pełne-wykluczające / anty połączenia
Jeśli potrzebujesz lewo-wykluczając połączenia i prawo-wykluczając połączenia w dwóch krokach.
Dla lewego-wyłączającego JOIN, reprezentowanego jako

Zacznij od wykonania lewej zewnętrznej Dołącz, a następnie filtruj (wyłączając!) wiersze pochodzące tylko z left,
(left.merge(right, on='key', how='left', indicator=True)
.query('_merge == "left_only"')
.drop('_merge', 1))
key value_x value_y
0 A 1.764052 NaN
2 C 0.978738 NaN
Gdzie,
left.merge(right, on='key', how='left', indicator=True)
key value_x value_y _merge
0 A 1.764052 NaN left_only
1 B 0.400157 1.867558 both
2 C 0.978738 NaN left_only
3 D 2.240893 -0.977278 bothI podobnie, dla łącznika wykluczającego prawo,

(left.merge(right, on='key', how='right', indicator=True)
.query('_merge == "right_only"')
.drop('_merge', 1))
key value_x value_y
2 E NaN 0.950088
3 F NaN -0.151357Na koniec, jeśli wymagane jest połączenie, które zachowuje tylko klucze z lewej lub prawej strony, ale nie oba (IOW, wykonując anty-JOIN ),

Można to zrobić w podobny sposób -
(left.merge(right, on='key', how='outer', indicator=True)
.query('_merge != "both"')
.drop('_merge', 1))
key value_x value_y
0 A 1.764052 NaN
2 C 0.978738 NaN
4 E NaN 0.950088
5 F NaN -0.151357
Różne nazwy kolumn kluczowych
Jeśli kolumny kluczowe są nazwane inaczej-na przykład left ma keyLeft, a right ma keyRight zamiast key - wtedy będziesz musiał podać left_on i right_on jako argumenty zamiast on:
left2 = left.rename({'key':'keyLeft'}, axis=1)
right2 = right.rename({'key':'keyRight'}, axis=1)
left2
keyLeft value
0 A 1.764052
1 B 0.400157
2 C 0.978738
3 D 2.240893
right2
keyRight value
0 B 1.867558
1 D -0.977278
2 E 0.950088
3 F -0.151357
left2.merge(right2, left_on='keyLeft', right_on='keyRight', how='inner')
keyLeft value_x keyRight value_y
0 B 0.400157 B 1.867558
1 D 2.240893 D -0.977278
Unikanie zduplikowanej kolumny klawiszy na wyjściu
Podczas scalania na keyLeft z left i keyRight z right, jeśli chcesz tylko jeden z keyLeft lub keyRight (ale nie oba) w wyjściu, możesz zacząć od ustawienia indeksu jako wstępnego kroku.
left3 = left2.set_index('keyLeft')
left3.merge(right2, left_index=True, right_on='keyRight')
value_x keyRight value_y
0 0.400157 B 1.867558
1 2.240893 D -0.977278
Wyjście polecenia tuż przed (to jest wyjście left2.merge(right2, left_on='keyLeft', right_on='keyRight', how='inner')), zauważysz keyLeft brakuje. Możesz dowiedzieć się, którą kolumnę zachować, na podstawie której indeks ramki jest ustawiony jako klucz. Może to mieć znaczenie, gdy, powiedzmy, wykonując jakąś operację połączenia zewnętrznego.
Łączenie tylko jednej kolumny z jednego z DataFrames
Na przykład, rozważmy
right3 = right.assign(newcol=np.arange(len(right)))
right3
key value newcol
0 B 1.867558 0
1 D -0.977278 1
2 E 0.950088 2
3 F -0.151357 3
Jeśli wymagane jest połączenie tylko "new_val" (bez żadnej z pozostałych kolumn), zwykle można po prostu kolumny podzbiorów przed scaleniem:
left.merge(right3[['key', 'newcol']], on='key')
key value newcol
0 B 0.400157 0
1 D 2.240893 1
map:
# left['newcol'] = left['key'].map(right3.set_index('key')['newcol']))
left.assign(newcol=left['key'].map(right3.set_index('key')['newcol']))
key value newcol
0 A 1.764052 NaN
1 B 0.400157 0.0
2 C 0.978738 NaN
3 D 2.240893 1.0
Jak wspomniano, jest to podobne do, ale szybsze niż
left.merge(right3[['key', 'newcol']], on='key', how='left')
key value newcol
0 A 1.764052 NaN
1 B 0.400157 0.0
2 C 0.978738 NaN
3 D 2.240893 1.0
Łączenie na wielu kolumnach
Aby dołączyć do więcej niż jednej kolumny, określ listę dla on (lub left_on i right_on, odpowiednio).
left.merge(right, on=['key1', 'key2'] ...)
Lub, w przypadku, gdy nazwy są inne,
left.merge(right, left_on=['lkey1', 'lkey2'], right_on=['rkey1', 'rkey2'])
Inne przydatne merge* operacje i funkcje
-
Łączenie ramki danych z seriami na indeksie: Patrz ta odpowiedź .
-
Poza tym
merge,DataFrame.updateorazDataFrame.combine_firstsą również używane w niektórych przypadkach do aktualizacji jednej ramki danych z inną. -
pd.merge_orderedjest przydatną funkcją dla uporządkowanych połączeń. -
pd.merge_asof(przeczytaj: merge_asOf) jest przydatne dla przybliżone / align = "left" /
Ta sekcja obejmuje tylko same podstawy i ma na celu tylko zaostrzyć apetyt. Więcej przykładów i przypadków można znaleźć w dokumentacji na merge, join, oraz concat jak również linki do specyfikacji funkcji.
Czytaj Dalej
Przejdź do innych tematów w Pandy 101 aby kontynuować naukę:
* jesteś tutaj
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-12-06 12:31:08
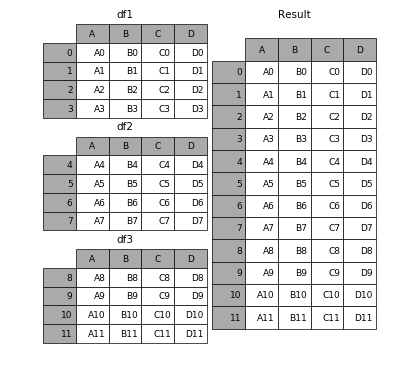
Uzupełniający obraz pd.concat([df0, df1], kwargs).
Zauważ, że znaczenie kwarg axis=0 lub axis=1 nie jest tak intuicyjne jak df.mean() lub df.apply(func)
![na pd.concat ([df0, DF1])](/images/content/46929420/ad090b7dd31e4dab7e82d065cb33a8a8.jpg)
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2019-10-11 17:36:29
W tej odpowiedzi rozważę praktyczne przykłady.
Pierwszy, jest z pandas.concat.
Drugi, scalający ramki danych z indeksu jednego i kolumny drugiego.
Biorąc pod uwagę następujące {[4] } o tych samych nazwach kolumn:
Preco2018 with size (8784, 5)

Preco 2019 z rozmiarem (8760, 5)

Które mają te same nazwy kolumn.
Można je łączyć za pomocą pandas.concat, by simply
import pandas as pd
frames = [Preco2018, Preco2019]
df_merged = pd.concat(frames)
Co daje ramkę danych o następującym rozmiarze (17544, 5)

Jeśli chcesz wizualizować, kończy się to tak
(źródło)
2. Merge by Column and Index
W tej części rozważę przypadek szczególny: jeżeli chcemy połączyć indeks jednej ramki z kolumną innej ramki.
Powiedzmy, że jeden ma ramkę danych Geo z 54 kolumnami, będącą jedną z kolumn daty Data, która jest typu datetime64[ns].

I ramka danych Price, która ma jedną kolumnę z ceną i indeksem odpowiada datom
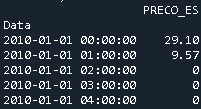
W tym konkretnym przypadku, aby je połączyć, używa się pd.merge
merged = pd.merge(Price, Geo, left_index=True, right_on='Data')
Co daje następujący dataframe

Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2021-01-24 00:26:49
[[40]}ten post będzie poruszał następujące tematy: [41]}
- łączenie z indeksem w różnych warunkach
- opcje połączeń opartych na indeksach:
merge,join,concat - scalanie na indeksach
- scalanie na indeksie jednej kolumny drugiej
- opcje połączeń opartych na indeksach:
- efektywne wykorzystanie nazwanych indeksów do uproszczenia składni scalania
Oparte na indeksie dołącza
TL;DR
Istnieje kilka opcji, niektóre prostsze niż inne w zależności od zastosowania case.
DataFrame.mergeZleft_indexiright_index(lubleft_oniright_onza pomocą indeksów nazw)
- obsługuje wewnętrzne / lewe / prawe / pełne
Może dołączyć tylko do dwóch na raz.]}- obsługuje połączenia column-column, index-column, index-index
DataFrame.join(dołącz do indeksu)
- podpory wewnętrzne / lewe (domyślnie) / right / full
Może łączyć się z wieloma ramami danych naraz.]}- obsługuje połączenia indeks-indeks
pd.concat(dołącza do indeksu)
- obsługuje wewnętrzny / pełny (domyślnie)
Może łączyć się z wieloma ramami danych naraz.]}- obsługuje połączenia indeks-indeks
Indeks do indeksu
Konfiguracja I Podstawy
import pandas as pd
import numpy as np
np.random.seed([3, 14])
left = pd.DataFrame(data={'value': np.random.randn(4)},
index=['A', 'B', 'C', 'D'])
right = pd.DataFrame(data={'value': np.random.randn(4)},
index=['B', 'D', 'E', 'F'])
left.index.name = right.index.name = 'idxkey'
left
value
idxkey
A -0.602923
B -0.402655
C 0.302329
D -0.524349
right
value
idxkey
B 0.543843
D 0.013135
E -0.326498
F 1.385076
Zazwyczaj, wewnętrzne połączenie na indeksie będzie wygląda tak:
left.merge(right, left_index=True, right_index=True)
value_x value_y
idxkey
B -0.402655 0.543843
D -0.524349 0.013135
Inne połączenia mają podobną składnię.
Godne Uwagi Alternatywy
-
DataFrame.joindomyślnie dołącza do indeksu.DataFrame.joindomyślnie wykonuje lewe złączenie zewnętrzne, więchow='inner'jest tutaj konieczne.left.join(right, how='inner', lsuffix='_x', rsuffix='_y') value_x value_y idxkey B -0.402655 0.543843 D -0.524349 0.013135Zauważ, że musiałem podać argumenty
lsuffixirsuffix, ponieważjoinw przeciwnym razie popełniłbym błąd:left.join(right) ValueError: columns overlap but no suffix specified: Index(['value'], dtype='object')Ponieważ nazwy kolumn są takie same. Nie byłoby to problemem, gdyby byli inaczej nazwane.
left.rename(columns={'value':'leftvalue'}).join(right, how='inner') leftvalue value idxkey B -0.402655 0.543843 D -0.524349 0.013135 -
pd.concatdołącza do indeksu i może dołączyć dwa lub więcej ramek danych jednocześnie. Domyślnie wykonuje pełne połączenie zewnętrzne, więchow='inner'jest tutaj wymagane..pd.concat([left, right], axis=1, sort=False, join='inner') value value idxkey B -0.402655 0.543843 D -0.524349 0.013135Aby uzyskać więcej informacji na temat
concat, Zobacz ten post .
Indeks do kolumn
Aby wykonać połączenie wewnętrzne za pomocą indeksu lewej, kolumny prawej, użyjesz DataFrame.merge kombinacji left_index=True i right_on=....
right2 = right.reset_index().rename({'idxkey' : 'colkey'}, axis=1)
right2
colkey value
0 B 0.543843
1 D 0.013135
2 E -0.326498
3 F 1.385076
left.merge(right2, left_index=True, right_on='colkey')
value_x colkey value_y
0 -0.402655 B 0.543843
1 -0.524349 D 0.013135
Inne połączenia mają podobną strukturę. Zauważ, że tylko merge może wykonywać indeks do łączenia kolumn. Możesz dołączyć do wielu kolumn, pod warunkiem, że liczba poziomów indeksów po lewej jest równa liczbie kolumn po prawej.
join i concat nie są zdolne do mieszania. Będziesz musiał ustawić indeks jako wstępny krok za pomocą DataFrame.set_index.
Efektywnie używając nazwanego indeksu [pandy >= 0.23]
Jeśli indeks jest nazwany, to z pandy > = 0.23, DataFrame.merge pozwala określić nazwę indeksu na on (lub left_on i right_on w razie potrzeby).
left.merge(right, on='idxkey')
value_x value_y
idxkey
B -0.402655 0.543843
D -0.524349 0.013135
W poprzednim przykładzie scalania z indeksem lewej, prawej kolumny, możesz użyć {[15] } z nazwą indeksu lewej:
left.merge(right2, left_on='idxkey', right_on='colkey')
value_x colkey value_y
0 -0.402655 B 0.543843
1 -0.524349 D 0.013135
Czytaj Dalej
Przejdź do innych tematów w Pandy 101 aby kontynuować naukę:
* jesteś tutaj
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-12-06 12:56:51
Ten post będzie poruszał następujące tematy:
- Jak poprawnie uogólnić na wiele ramek danych (i dlaczego
mergema tutaj braki) - scalanie na unikalnych kluczach
- scalanie na nie-unqiue keys
Uogólnienie na wiele ramek danych
Często pojawia się sytuacja, gdy wiele ramek danych ma być połączonych ze sobą. Naiwnie, można to zrobić poprzez wywołania łańcucha merge:
df1.merge(df2, ...).merge(df3, ...)
Jednak to szybko wymyka się spod kontroli dla wielu ramek danych. Ponadto konieczne może być uogólnienie dla nieznanej liczby ramek danych.
Tutaj przedstawiam pd.concat dla połączeń wielokierunkowych na klawiszach unique oraz DataFrame.join dla połączeń wielokierunkowych na klawiszach non-unique {46]}. Najpierw konfiguracja.
# Setup.
np.random.seed(0)
A = pd.DataFrame({'key': ['A', 'B', 'C', 'D'], 'valueA': np.random.randn(4)})
B = pd.DataFrame({'key': ['B', 'D', 'E', 'F'], 'valueB': np.random.randn(4)})
C = pd.DataFrame({'key': ['D', 'E', 'J', 'C'], 'valueC': np.ones(4)})
dfs = [A, B, C]
# Note, the "key" column values are unique, so the index is unique.
A2 = A.set_index('key')
B2 = B.set_index('key')
C2 = C.set_index('key')
dfs2 = [A2, B2, C2]
Multiway merge on unique keys
Jeśli Twoje klucze (tutaj kluczem może być kolumna lub Indeks) to unique, wtedy możesz użyć pd.concat. Zauważ, że pd.concat dołącza ramki danych do indeksu .
# merge on `key` column, you'll need to set the index before concatenating
pd.concat([
df.set_index('key') for df in dfs], axis=1, join='inner'
).reset_index()
key valueA valueB valueC
0 D 2.240893 -0.977278 1.0
# merge on `key` index
pd.concat(dfs2, axis=1, sort=False, join='inner')
valueA valueB valueC
key
D 2.240893 -0.977278 1.0
Pomiń join='inner' dla pełnego połączenia zewnętrznego. Zauważ, że nie możesz określić lewego lub prawego złączenia Zewnętrznego (jeśli potrzebujesz, użyj join, opisanego poniżej).
Multiway merge na kluczach z duplikatami
concat jest szybki, ale ma swoje wady. Nie radzi sobie z duplikatami.
A3 = pd.DataFrame({'key': ['A', 'B', 'C', 'D', 'D'], 'valueA': np.random.randn(5)})
pd.concat([df.set_index('key') for df in [A3, B, C]], axis=1, join='inner')
ValueError: Shape of passed values is (3, 4), indices imply (3, 2)
W tej sytuacji możemy użyć join, ponieważ może obsłużyć nie unikalne keys (zauważ, że join dołącza ramki danych do ich indeksu; wywołuje merge pod maską i wykonuje lewe zewnętrzne połączenie, chyba że określono inaczej).
# join on `key` column, set as the index first
# For inner join. For left join, omit the "how" argument.
A.set_index('key').join(
[df.set_index('key') for df in (B, C)], how='inner').reset_index()
key valueA valueB valueC
0 D 2.240893 -0.977278 1.0
# join on `key` index
A3.set_index('key').join([B2, C2], how='inner')
valueA valueB valueC
key
D 1.454274 -0.977278 1.0
D 0.761038 -0.977278 1.0
Czytaj Dalej
Przejdź do innych tematów w Pandy 101 aby kontynuować naukę:
* jesteś tutaj
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2020-12-06 12:56:31