C++11 wprowadził ustandaryzowany model pamięci. Co to znaczy? A jak to wpłynie na programowanie w C++?
C++11 wprowadził ustandaryzowany model pamięci, ale co to dokładnie oznacza? A jak to wpłynie na programowanie w C++?
Ten artykuł (autorstwa Gavina Clarke ' a , który cytuje Herb Sutter ) mówi, że
Model pamięci oznacza, że kod C++ teraz ma znormalizowaną bibliotekę do wywołania niezależnie od tego, kto stworzył kompilator i na jakiej platformie działa. Jest standardowy sposób kontrolowania jak różne wątki rozmawiają z pamięć procesora.
"Kiedy mówisz o rozdzieleniu [kod] w różnych rdzeniach to w standardzie mówimy o model pamięci. Zamierzamy Optymalizuj go bez łamania zgodnie z założeniami ludzie idą aby w kodzie, " Sutter powiedział.
No cóż, mogę zapamiętać ten i podobne akapity dostępne w internecie (bo od urodzenia miałem swój własny model pamięci :P) i mogę nawet pisać jako odpowiedź na pytania zadawane przez innych, ale szczerze mówiąc, nie do końca to Rozumiem.
Więc, to, co w zasadzie chcę wiedzieć, jest, Programiści C++ używane do tworzenia wielowątkowych aplikacji nawet wcześniej, więc jakie to ma znaczenie, czy to wątki POSIX, lub wątki Windows, lub C++11 wątki? Jakie są korzyści? Chcę zrozumieć szczegóły niskiego poziomu.
Mam też wrażenie, że model pamięci C++11 jest w jakiś sposób związany z obsługą wielowątkową C++11, ponieważ często widzę te dwa razem. Jeśli tak, to w jaki sposób? Dlaczego mieliby być spokrewnieni?
Ponieważ Nie wiem, jak działa wewnętrzne wielowątkowość i co ogólnie oznacza model pamięci, proszę o pomoc w zrozumieniu tych pojęć. :-)
6 answers
Najpierw musisz nauczyć się myśleć jak prawnik językowy.
Specyfikacja C++ nie odnosi się do żadnego konkretnego kompilatora, systemu operacyjnego lub procesora. Odnosi się ona do maszyny abstrakcyjnej, która jest uogólnieniem systemów rzeczywistych. W świecie języka zadaniem programisty jest pisanie kodu dla maszyny abstrakcyjnej; zadaniem kompilatora jest urzeczywistnienie tego kodu na konkretnej maszynie. Kodując sztywno do specyfikacji, możesz być pewność, że Twój kod będzie kompilowany i uruchamiany Bez Modyfikacji na dowolnym systemie z kompatybilnym kompilatorem C++, czy to dzisiaj, czy za 50 lat.
Maszyna abstrakcyjna w specyfikacji C++98/C++03 jest zasadniczo jednowątkowa. Nie jest więc możliwe napisanie wielowątkowego kodu C++, który jest "w pełni przenośny" w odniesieniu do specyfikacji. Spec nie mówi nawet nic o atomiczności ładowań i magazynów pamięci ani o porządku, w którym ładuje i sklepy mogą się zdarzyć, nieważne jak mutexy.
Oczywiście można pisać wielowątkowy kod w praktyce dla konkretnych systemów-takich jak pthreads lub Windows. Ale nie ma standardowego sposobu zapisu wielowątkowego kodu dla C++98/C++03.
Maszyna abstrakcyjna w C++11 jest wielowątkowa. Ma również dobrze zdefiniowany model pamięci ; to znaczy mówi, co kompilator może, a czego nie, jeśli chodzi o dostęp pamięć.
Rozważ następujący przykład, w którym para zmiennych globalnych jest dostępna jednocześnie przez dwa wątki:
Global
int x, y;
Thread 1 Thread 2
x = 17; cout << y << " ";
y = 37; cout << x << endl;
Jaki może być wynik wątku 2?
W C++98/C++03 nie jest to nawet niezdefiniowane zachowanie; samo pytanie jest bez znaczenia, ponieważ standard nie rozważa niczego, co nazywa się "wątkiem".
W C++11 wynik jest niezdefiniowany, ponieważ ładunki i magazyny nie muszą być atomowe w ogóle. Co może się nie wydawać coś w tym stylu... I sama w sobie nie jest.
Ale z C++11 możesz napisać tak:
Global
atomic<int> x, y;
Thread 1 Thread 2
x.store(17); cout << y.load() << " ";
y.store(37); cout << x.load() << endl;
Teraz rzeczy stają się o wiele bardziej interesujące. Po pierwsze, zachowanie tutaj jest zdefiniowane . Wątek 2 może teraz drukować 0 0 (jeśli działa przed wątkiem 1), 37 17 (jeśli działa po wątku 1), lub 0 17 (jeśli działa po wątku 1 przypisuje X, ale przed przypisaniem y).
Nie może wydrukować 37 0, ponieważ domyślny tryb dla obciążeń atomowych / przechowuje w C++11 jest wymuszenie sekwencyjnej spójności. Oznacza to po prostu, że wszystkie ładunki i sklepy muszą być" tak, jakby " miały miejsce w kolejności, w jakiej je napisałeś w każdym wątku, podczas gdy operacje między wątkami mogą być przeplatane, jakkolwiek system lubi. Tak więc domyślne zachowanie atomiki zapewnia zarówno atomiczność, jak i zamawianie dla ładunków i magazynów.
Teraz, na nowoczesnym procesorze, zapewnienie spójności sekwencyjnej może być kosztowne. W szczególności kompilator może emitować pełne bariery pamięci między każdym dostępem tutaj. Ale jeśli twój algorytm toleruje ładunki poza porządkiem i przechowuje; tzn. jeśli wymaga atomiczności, ale nie porządkowania; tzn. jeśli toleruje 37 0 jako wyjście z tego programu, możesz napisać to:
Global
atomic<int> x, y;
Thread 1 Thread 2
x.store(17,memory_order_relaxed); cout << y.load(memory_order_relaxed) << " ";
y.store(37,memory_order_relaxed); cout << x.load(memory_order_relaxed) << endl;
Im bardziej nowoczesny procesor, tym bardziej prawdopodobne, że będzie szybszy niż poprzedni przykład.
Na koniec, jeśli potrzebujesz tylko zachować porządek w poszczególnych ładunkach i magazynach, możesz napisać:
Global
atomic<int> x, y;
Thread 1 Thread 2
x.store(17,memory_order_release); cout << y.load(memory_order_acquire) << " ";
y.store(37,memory_order_release); cout << x.load(memory_order_acquire) << endl;
This takes us wracając do zamówionych ładunków i magazynów-więc 37 0 nie jest już możliwym wyjściem - ale robi to przy minimalnym obciążeniu. (W tym trywialnym przykładzie wynik jest taki sam jak pełnowymiarowa spójność Sekwencyjna; w większym programie nie byłoby.)
Oczywiście, jeśli jedyne wyjścia, które chcesz zobaczyć to 0 0 lub 37 17, możesz po prostu owinąć mutex wokół oryginalnego kodu. Ale jeśli przeczytałeś tak daleko, założę się, że już wiesz, jak to działa, a ta odpowiedź jest już dłuższa niż ja zamierzony : -).
Więc, podsumowując. Muteksy są świetne, A C++11 je standaryzuje. Ale czasami ze względu na wydajność potrzebujesz prymitywów niższego poziomu (np. klasyczny podwójnie sprawdzony wzór blokowania). Nowy standard zapewnia gadżety wysokiego poziomu, takie jak muteksy i zmienne stanu, a także zapewnia gadżety niskiego poziomu, takie jak typy atomowe i różne smaki bariery pamięci. Więc teraz możesz pisać wyrafinowane, wysokowydajne procedury współbieżne całkowicie w języku określonym przez standard, możesz być pewien, że Twój kod będzie kompilowany i uruchamiany bez zmian zarówno na dzisiejszych, jak i jutrzejszych systemach.]}
Chociaż szczerze mówiąc, jeśli nie jesteś ekspertem i nie pracujesz nad jakimś poważnym niskopoziomowym kodem, prawdopodobnie powinieneś trzymać się muteksów i zmiennych warunkowych. To właśnie zamierzam zrobić.
Aby dowiedzieć się więcej na ten temat, zobacz ten wpis na blogu.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-11-06 03:35:04
Podam tylko analogię, z którą Rozumiem modele spójności pamięci (lub modele pamięci, w skrócie). Inspiracją do jego powstania była praca Leslie Lamport "Time, Clocks, and the Ordering of Events in a Distributed System" . Analogia jest trafna i ma fundamentalne znaczenie, ale może być przesadą dla wielu ludzi. Mam jednak nadzieję, że zapewnia obraz mentalny (obrazkową reprezentację), który ułatwia rozumowanie o modelach spójności pamięci.
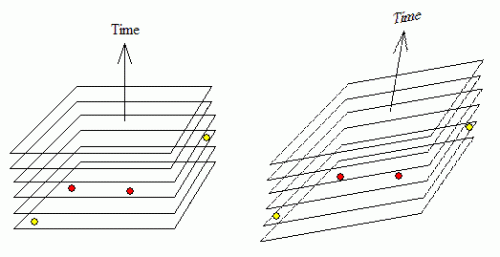
Let ' s view the historie wszystkich lokalizacji pamięci na diagramie czasoprzestrzeni, w którym oś pozioma reprezentuje przestrzeń adresową (tzn. każda lokalizacja pamięci jest reprezentowana przez punkt na tej osi), a oś pionowa reprezentuje czas (zobaczymy, że ogólnie nie ma uniwersalnego pojęcia czasu). Historia wartości przechowywanych przez każdą lokalizację pamięci jest zatem reprezentowana przez pionową kolumnę pod tym adresem pamięci. Każda zmiana wartości jest spowodowana przez jeden z wątków piszących nową wartość do tego miejsce. Przez a obraz pamięci, będziemy oznaczać agregację / kombinację wartości wszystkich miejsc pamięci obserwowalnych w określonym czasie przez konkretny wątek.
Cytowanie z "podkład o spójności pamięci i spójności pamięci podręcznej"
Intuicyjny (i najbardziej restrykcyjny) model pamięci to Sekwencyjna spójność (SC), w której wielowątkowe wykonanie powinno wyglądać jak przeplatanie sekwencyjnego wykonywanie każdego składowego wątku, tak jakby wątki były multipleksowane w czasie na jednordzeniowym procesorze.
Ten globalny porządek pamięci może się różnić w zależności od uruchomienia programu i może nie być wcześniej znany. Cechą charakterystyczną SC jest zbiór przekrojów poziomych na diagramie adres-czasoprzestrzeń przedstawiający płaszczyzny symultaniczności (tj. obrazy pamięci). Na danej płaszczyźnie wszystkie jej zdarzenia (lub wartości pamięci) są równoczesne. Jest pojęcie czasu absolutnego , w którym wszystkie wątki zgadzają się, które wartości pamięci są jednocześnie. W SC za każdym razem jest tylko jeden obraz pamięci współdzielony przez wszystkie wątki. Oznacza to, że w każdej chwili wszystkie procesory zgadzają się na obraz pamięci (tj. zagregowaną zawartość pamięci). Oznacza to nie tylko, że wszystkie wątki wyświetlają tę samą sekwencję wartości dla wszystkich miejsc pamięci, ale także, że wszystkie procesory obserwują te same kombinacje wartości wszystkich zmienne. Jest to to samo, co stwierdzenie, że wszystkie operacje pamięci (na wszystkich miejscach pamięci) są obserwowane w tej samej całkowitej kolejności przez wszystkie wątki.
W luźnych modelach pamięci, każdy wątek pokroi adres-czasoprzestrzeń na swój sposób, jedynym ograniczeniem jest to, że plasterki każdego wątku nie krzyżują się ze sobą, ponieważ wszystkie wątki muszą zgadzać się co do historii każdej pojedynczej lokalizacji pamięci (oczywiście plasterki różnych wątków mogą i będą się krzyżować). Nie ma uniwersalnego sposób na pokrojenie (brak uprzywilejowanej foliacji adres-czasoprzestrzeń). Plastry nie muszą być płaskie (lub liniowe). Mogą być zakrzywione i to może sprawić, że wątek odczyta wartości zapisane przez inny wątek w kolejności, w jakiej zostały napisane. Historie różnych miejsc pamięci mogą przesuwać się (lub rozciągać) dowolnie względem siebie gdy oglądany przez dowolny wątek. Każdy wątek będzie miał Inne Poczucie, które zdarzenia (lub, równoważnie, wartości pamięci) są równoczesne. Zbiór zdarzeń (lub wartości pamięci), które są równoczesne dla jednego wątku, nie jest jednoczesny dla drugiego. Tak więc, w modelu pamięci swobodnej, wszystkie wątki nadal obserwują tę samą historię (tj. sekwencję wartości) dla każdej lokalizacji pamięci. Ale mogą obserwować różne obrazy pamięci (tj. kombinacje wartości wszystkich miejsc pamięci). Nawet jeśli dwa różne miejsca pamięci są zapisywane przez ten sam wątek w kolejności, dwie nowo zapisane wartości mogą być obserwowane w różnych kolejność według innych wątków.
[zdjęcie z Wikipedii]
Czytelnicy zaznajomieni ze specjalną teorią względności Einsteina zauważą, do czego nawiązuję. Tłumaczenie słów Minkowskiego na sferę modeli pamięci: przestrzeń adresowa i czas to cienie adres-czasoprzestrzeń. W tym przypadku każdy obserwator (tj. wątek) będzie rzutować cienie zdarzeń (tj. zapasy pamięci/obciążenia) na własną linię świata (tj. jego oś czasu) i własną płaszczyznę jednoczesności (jego adres-oś przestrzeni). Wątki w modelu pamięci C++11 odpowiadają obserwatorzy które poruszają się względem siebie w szczególnej teorii względności. Sekwencyjna spójność odpowiada Galilejskiej czasoprzestrzeni (tzn. wszyscy obserwatorzy zgadzają się na jeden absolutny porządek zdarzeń i globalne poczucie jednoczesności).
Podobieństwo między modelami pamięci a szczególną teorią względności wynika z faktu, że oba definiują częściowo uporządkowany zbiór zdarzeń, często nazywany przyczynowym gotowi. Niektóre zdarzenia (np. zapasy pamięci) mogą wpływać na inne zdarzenia (ale nie mogą być wpływane przez inne zdarzenia). Wątek C++11 (lub obserwator w fizyce) to nie więcej niż łańcuch (tj. całkowicie uporządkowany zbiór) zdarzeń (np. Ładowanie pamięci i zapisywanie ich na różne adresy).
W teorii względności, pewien porządek zostaje przywrócony pozornie chaotycznemu obrazowi częściowo uporządkowanych zdarzeń, ponieważ jedynym porządkiem czasowym, co do którego zgadzają się wszyscy obserwatorzy, jest porządek wśród zdarzeń "czasowych" (tj. tych zdarzeń, które są w zasadzie każda cząstka poruszająca się wolniej niż prędkość światła w próżni). Tylko zdarzenia związane z czasem są niezmiennie uporządkowane. Czas w fizyce, Craig Callender.
W modelu pamięci C++11, podobny mechanizm (model spójności acquire-release) jest używany do ustalenia tych lokalne stosunki przyczynowo-skutkowe.
Aby podać definicję spójności pamięci i motywację do porzucenia SC, zacytuję z " podkład na Spójność pamięci i spójność pamięci podręcznej "
Dla maszyny pamięci współdzielonej model spójności pamięci definiuje architektonicznie widoczne zachowanie jej systemu pamięci. Kryterium poprawności dla pojedynczego rdzenia procesora zachowuje się pomiędzy " one correct result " i " many incorrect alternatives ". Dzieje się tak dlatego, że architektura procesora nakazuje, aby wykonanie wątku przekształciło dany stan wejściowy w jedno dobrze zdefiniowane wyjście stan, nawet na pozasądowym rdzeniu. Modele spójności pamięci współdzielonej dotyczą jednak obciążeń i zapisów wielu wątków i zazwyczaj pozwalają na wiele poprawnych wykonań, przy czym nie pozwalają na wiele (więcej) błędnych. Możliwość wielokrotnego poprawnego wykonania wynika z ISA pozwalającego na jednoczesne wykonywanie wielu wątków, często z wieloma możliwymi legalnymi przerywnikami instrukcji z różnych wątków.
Relaxed lub słabe modele spójności pamięci są motywowane faktem, że większość porządków pamięci w silnych modelach jest niepotrzebna. Jeśli wątek aktualizuje dziesięć pozycji danych, a następnie flagę synchronizacji, Programiści zwykle nie dbają o to, czy pozycje danych są aktualizowane w kolejności względem siebie, ale tylko, że wszystkie pozycje danych są aktualizowane przed aktualizacją flagi (zwykle realizowane za pomocą instrukcji ogrodzenia). Zrelaksowane modele starają się uchwycić tę zwiększoną elastyczność zamawiania i zachować tylko te zamówienia, które Programiści " wymagają ", aby uzyskać zarówno wyższą wydajność, jak i poprawność SC. Na przykład w niektórych architekturach bufory zapisu FIFO są używane przez każdy rdzeń do przechowywania wyników zapisanych (wycofanych) zapisów przed zapisaniem wyników do pamięci podręcznej. Ta optymalizacja zwiększa wydajność, ale narusza SC. Bufor zapisu ukrywa opóźnienie obsługi miss sklepu. Ponieważ sklepy są powszechne, możliwość uniknięcia zwlekania z większością z nich jest ważną korzyścią. Dla jednordzeniowego procesor, bufor zapisu może być architektonicznie niewidoczny, zapewniając, że obciążenie adresowane do a Zwraca wartość najnowszego magazynu do a, nawet jeśli jeden lub więcej sklepów do A znajduje się w buforze zapisu. Zwykle odbywa się to poprzez pominięcie wartości najnowszego magazynu do A do obciążenia z A, gdzie "Najnowszy" jest określony przez kolejność programu, lub przez przeciągnięcie obciążenia a, jeśli magazyn do A znajduje się w buforze zapisu. W przypadku użycia wielu rdzeni, każdy z nich będzie miał swój własny zapis omijający bufor. Bez buforów zapisu sprzęt jest SC, ale z buforami zapisu nie jest, co sprawia, że bufory zapisu są architektonicznie widoczne w procesorze wielordzeniowym.
Store-Zmiana kolejności przechowywania może się zdarzyć, jeśli rdzeń ma bufor zapisu niezwiązany z FIFO, który pozwala sklepom odejść w innej kolejności niż kolejność, w której zostały wprowadzone. Może się to zdarzyć, jeśli pierwszy sklep nie trafi w pamięci podręcznej, podczas gdy drugi trafi lub jeśli drugi sklep może połączyć się z wcześniejszym sklepem (tj. przed pierwszym sklepem). Load-Zmiana kolejności obciążenia może się również zdarzyć na rdzeniach dynamicznie zaplanowanych, które wykonują instrukcje poza kolejnością programu. To może zachowywać się tak samo jak zmiana kolejności sklepów na innym rdzeniu (możesz wymyślić przykład przeplatania między dwoma wątkami?). Zmiana kolejności wcześniejszego obciążenia za pomocą późniejszego magazynu (Zmiana kolejności obciążenia-sklepu) może spowodować wiele nieprawidłowych zachowań, takich jak ładowanie wartości po zwolnieniu blokady, która ją chroni (jeśli sklep jest operacją odblokowania). Zwróć uwagę, że zmiana kolejności ładowania sklepu może powstają również z powodu lokalnego ominięcia w powszechnie zaimplementowanym buforze zapisu FIFO, nawet z rdzeniem wykonującym wszystkie instrukcje w kolejności programowej.
Ponieważ spójność pamięci podręcznej i spójność pamięci są czasami mylone, pouczające jest również posiadanie tego cytatu:
W przeciwieństwie do konsystencji, spójność pamięci podręcznej nie jest widoczny dla oprogramowania ani wymagany. Koherencja ma na celu uczynienie pamięci podręcznej systemu pamięci współdzielonej tak funkcjonalnie niewidoczną, jak pamięć podręczna w systemie jednordzeniowym. Poprawna koherencja zapewnia, że programista nie może określić, czy i gdzie system ma pamięć podręczną, analizując wyniki obciążeń i magazynów. Dzieje się tak dlatego, że poprawna spójność zapewnia, że pamięci podręczne nigdy nie włączają nowych lub innych funkcjonalne zachowanie (programiści mogą nadal być w stanie wywnioskować prawdopodobną strukturę pamięci podręcznej za pomocą Czas informacje). Głównym celem protokołów spójności pamięci podręcznej jest utrzymanie single-writer-multiple-readers (SWMR) niezmienny dla każdego miejsca pamięci. Ważnym rozróżnieniem między spójnością a spójnością jest to, że spójność jest określona na baza lokalizacji per-memory, natomiast spójność jest określona w odniesieniu do Wszystkie miejsca pamięci.
Kontynuując nasz obraz umysłowy, niezmiennik SWMR odpowiada fizycznemu wymogowi, że w dowolnym miejscu znajduje się co najwyżej jedna cząstka, ale tam może być nieograniczona liczba obserwatorów dowolnej lokalizacji.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-02-08 14:44:04
jest to pytanie sprzed wielu lat, ale będąc bardzo popularnym, warto wspomnieć o fantastycznym zasobie do nauki o modelu pamięci C++11. Nie widzę sensu w podsumowaniu jego wypowiedzi, żeby była to kolejna pełna odpowiedź, ale biorąc pod uwagę, że to on napisał standard, myślę, że warto obejrzeć rozmowę.
Herb Sutter ma trzygodzinną rozmowę na temat modelu pamięci C++11 zatytułowanego "atomic Weapons", dostępnego na stronie Channel9 - Część 1 i część 2 . Dyskusja jest dość techniczna i obejmuje następujące tematy:
- optymalizacje, rasy i model pamięci
- zamawianie-co: nabyć i zwolnić
- porządkowanie-jak: muteksy, Atomiki i / lub ogrodzenia
- inne ograniczenia dotyczące kompilatorów i sprzętu
- Kod Gen I Wydajność: x86/x64, IA64, POWER, ARM
- Relaxed Atomics
Dyskusja Nie dotyczy API, ale raczej rozumowanie, tło, pod maską i za kulisami (Czy wiesz, że luźna semantyka została dodana do standardu tylko dlatego, że moc i ramię nie obsługują efektywnie zsynchronizowanego obciążenia?).
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-11-05 23:17:25
Oznacza to, że standard definiuje teraz wielowątkowość i określa, co dzieje się w kontekście wielu wątków. Oczywiście, ludzie używali różnych implementacji, ale to jak pytanie, Dlaczego powinniśmy mieć std::string, kiedy wszyscy możemy używać klasy domowej string.
Kiedy mówisz o wątkach POSIX lub Windows, To jest to trochę złudzenie, ponieważ w rzeczywistości mówisz o wątkach x86, ponieważ jest to funkcja sprzętowa do jednoczesnego uruchamiania. Pamięć C++0x model daje gwarancje, czy jesteś na x86, czy ARM, czy MIPS , czy cokolwiek innego, co możesz wymyślić.
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-11-05 23:06:03
Dla języków, które nie określają modelu pamięci, piszemy kod dla języka i modelu pamięci określonego przez architekturę procesora. Procesor może zdecydować się na ponowne zamówienie dostępu do pamięci dla wydajności. Tak więc, Jeśli twój program ma wyścigi danych (wyścig danych jest wtedy, gdy możliwe jest, aby wiele rdzeni / hyper-wątków miało dostęp do tej samej pamięci jednocześnie), to twój program nie jest cross platform ze względu na jego zależność od modelu pamięci procesora. Możesz polecić do podręczników oprogramowania Intel lub AMD, aby dowiedzieć się, w jaki sposób procesory mogą ponownie zamówić dostęp do pamięci.
Co bardzo ważne, blokady (i semantyka współbieżności z blokowaniem) są zazwyczaj implementowane w sposób wieloplatformowy... Więc jeśli używasz standardowych zamków w programie wielowątkowym bez wyścigów danych, to nie musisz się martwić o wieloplatformowe modele pamięci .
Co ciekawe, Kompilatory Microsoftu dla C++ posiadają semantykę volatile czyli C++ rozszerzenie do radzenia sobie z brakiem modelu pamięci w C++ http://msdn.microsoft.com/en-us/library/12a04hfd (V = vs.80). aspx. jednak biorąc pod uwagę, że Windows działa tylko na x86 / x64 ,to niewiele mówi (modele pamięci Intel i AMD ułatwiają i wydajnie implementują semantykę acquire / release w danym języku).
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2017-11-05 23:09:19
Jeśli używasz mutexów do ochrony wszystkich danych, naprawdę nie powinieneś się martwić. Mutexy zawsze zapewniały wystarczające gwarancje zamawiania i widoczności.
Teraz, jeśli używałeś atomiki lub algorytmów bez blokady, musisz pomyśleć o modelu pamięci. Model pamięci dokładnie opisuje, kiedy atomika zapewnia gwarancję uporządkowania i widoczności, a także zapewnia przenośne ogrodzenia dla ręcznych gwarancji.
Wcześniej atomika byłaby wykonywana przy użyciu kompilatora, lub jakiegoś biblioteka wyższego poziomu. Ogrodzenia byłyby wykonywane przy użyciu instrukcji specyficznych dla procesora (bariery pamięci).
Warning: date(): Invalid date.timezone value 'Europe/Kyiv', we selected the timezone 'UTC' for now. in /var/www/agent_stack/data/www/doraprojects.net/template/agent.layouts/content.php on line 54
2011-06-11 23:49:53